

フェイス・ソリューション・テクノロジーズ株式会社 IS 本部 OS ユニットの masです。
前回に引き続き、今回はAthenaでデータベースを作成して実際にデータを検索する手順をご紹介したいと思います。
手順紹介
データベースを作成する
初期設定
まずAthena コンソールを開いてください。

初めてAthenaを使う場合は「最初のクエリを実行する前に~」のところの設定を編集をクリック
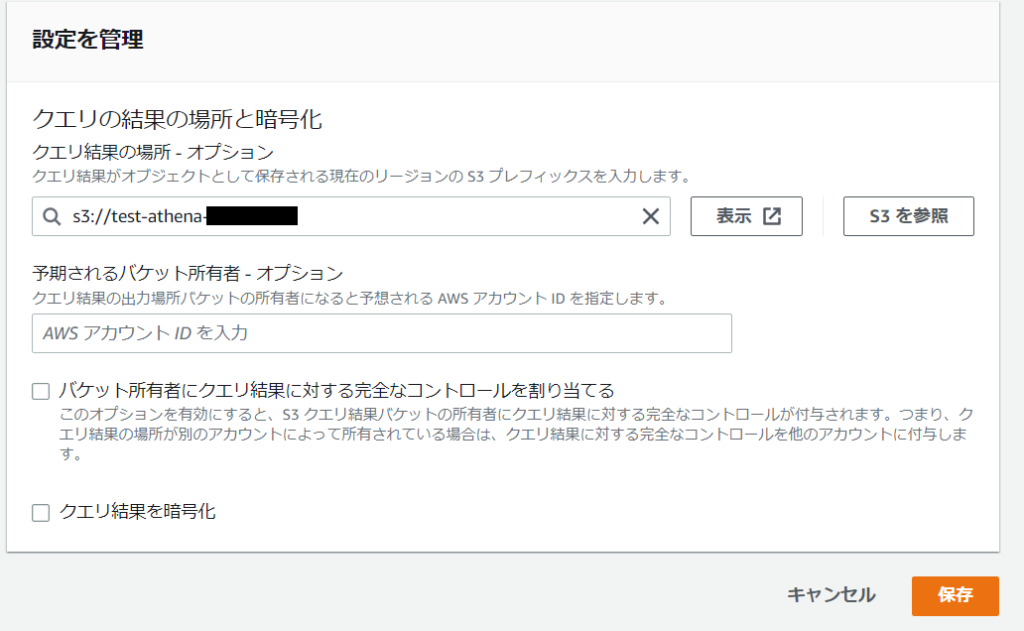
クエリ結果を出力するS3bucketを指定して保存をクリック
データベースを作成
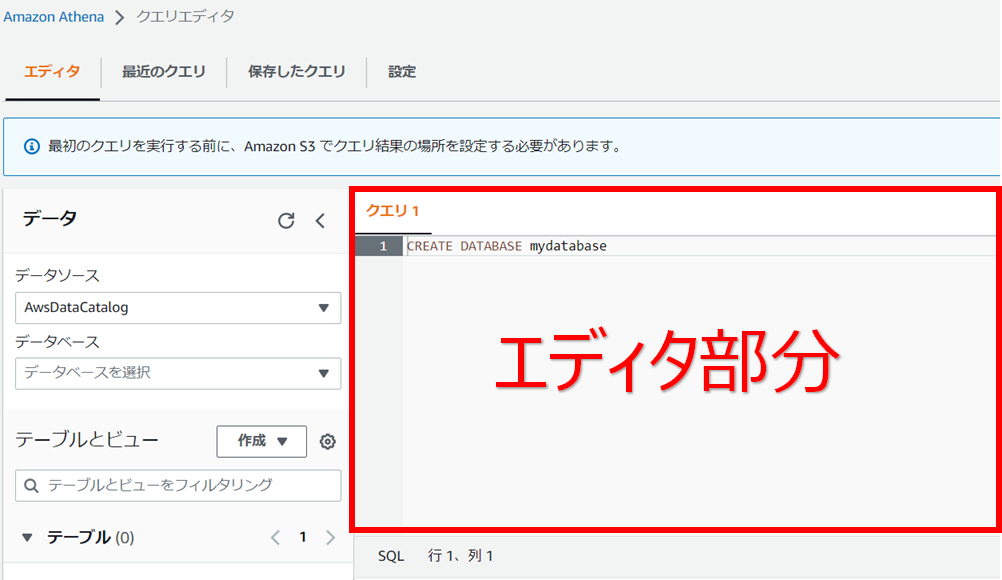
クエリエディタ画面でエディタ部分に下記のクエリを入力
CREATE DATABASE <データベース名>実行をクリックする。
データベースのところに作成したデータベース名が出てきたら作成完了
バケットに検索対象のCSVを配置
今回は総務省統計局のサイトから取得したオープンデータを使用しました。
任意の名前でバケットを作成し、用意したCSVを配置します。

テーブルの作成の項目で紹介するクエリ部分で使用する為、作成したバケット名を控えておいてください。
テーブルの作成
エディタ部分に下記を入力して実行を押します。
問題がなければクエリ結果に「クエリは成功しました。」と表示され、
さらにテーブルのところに作成したテーブルの名前が表示されます。
CREATE EXTERNAL TABLE IF NOT EXISTS test(
`ID` STRING,
`class` STRING,
`class_L` STRING,
`class_M` STRING,
`Class_S` STRING,
`category` STRING,
`Jan` STRING,
`Feb` STRING,
`Mar` STRING,
`Apr` STRING,
`May` STRING,
`Jun` STRING,
`Jul` STRING,
`Aug` STRING,
`Sep` STRING,
`Oct` STRING,
`Nov` STRING,
`Dec` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'integerization.format' = ',', 'field.delim' = ',' )
LOCATION < 検索対象になっているbucket >
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='4', 'serialization.encoding'='SJIS')簡単にコード解説
CREATE EXTERNAL TABLE IF NOT EXISTS 'table_name'「CREATE EXTERNAL TABLE」はテーブル作成時の決まり文句。
「IF NOT EXISTS ‘table_name’」で同名のテーブルが見つからない時だけ作成します。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'integerization.format' = ',', 'field.delim' = ',' ) SerDe(シリアライザー/デシリアライザー)の設定を書いています。
Ahenaが読み込んだデータを取り扱う際のルールです。
エスケープ文字だったり、列の区切り文字などを設定してます。
LOCATION < 検索対象になっているbucket >どのバケットをテーブルとして扱うかを設定する。
ファイルじゃなくバケットを指定するところが重要
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='4', 'serialization.encoding'='SJIS')テーブルのプロパティ設定をしている箇所になります。
不要な行があった場合は「skip.header.line.count」で飛ばす行数を設定します。
実際に検索をかけてみる
下記のクエリを実行する。
SELECT * FROM test WHERE category IN('穀類','魚介類','肉類')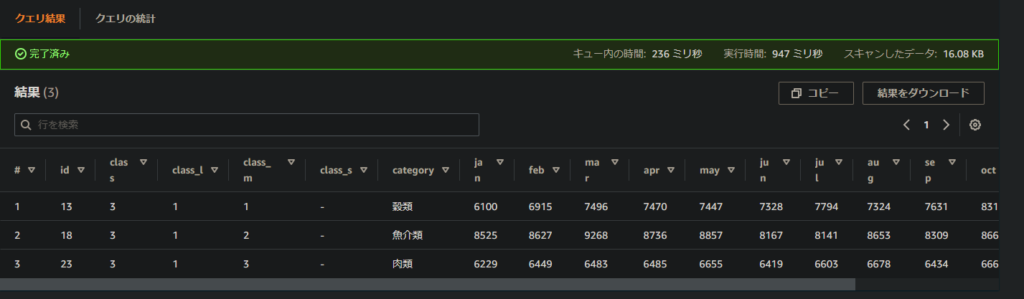
クエリ結果のところに結果が表示されます。
結果CSVの出力先
初期設定時にクエリ結果の出力先に指定したbucket内に実行結果のcsvが生成されています。
最後に
以上で、Athenaを使って実際にデータを検索する手順を紹介しました。
今回はパーティションという機能を使用しませんでしたが、パーティションを使用すると
パフォーマンスを向上させ、さらにはコストカットもできるようになります。
そこで次回は、パーティションについて説明し、実際にパーティションを使用する手法について
ご紹介したいと思います。
次回も何卒宜しくお願い致します。

コメント