

Athenaを使ったデータベース学習
<初めに>
応用情報技術者試験も終わり、10月のデータベーススペシャリストの勉強を開始するにあたって実践的な勉強をしたいと考えてAthenaを勉強することにしました。ユニット長に課題を作ってもらったのでその課題を実践した記録を記しておきます。何かのお役に立てると幸いです。
※今回のブログはユニット長に課題を添削してもらってから書いているのでSQL文など見やすくなっているとは思いますが、直し切れていない箇所もあるかもしれないので適宜ご指摘いただけるとうれしいです。
<初期段階>
プライベートで作成したAWSアカウントがあるのでこちらを使用しました。また使用するデータは課題をいただいたときにもらったものを使用しています。(郵便番号のリストです。)
課題① Aデータ(CSVファイル)をS3に保存し、Athenaでテーブルを作成する
1.S3バケットの作成・Aファイルの保存
まず、データをS3に保存するためにs3バケットを作成します。AWSコンソール画面の検索ボックスにs3と入力し下記画面に移動します。

この画面に移動したらバケットの作成を押し次に進みます。次の画面が下の画像です。
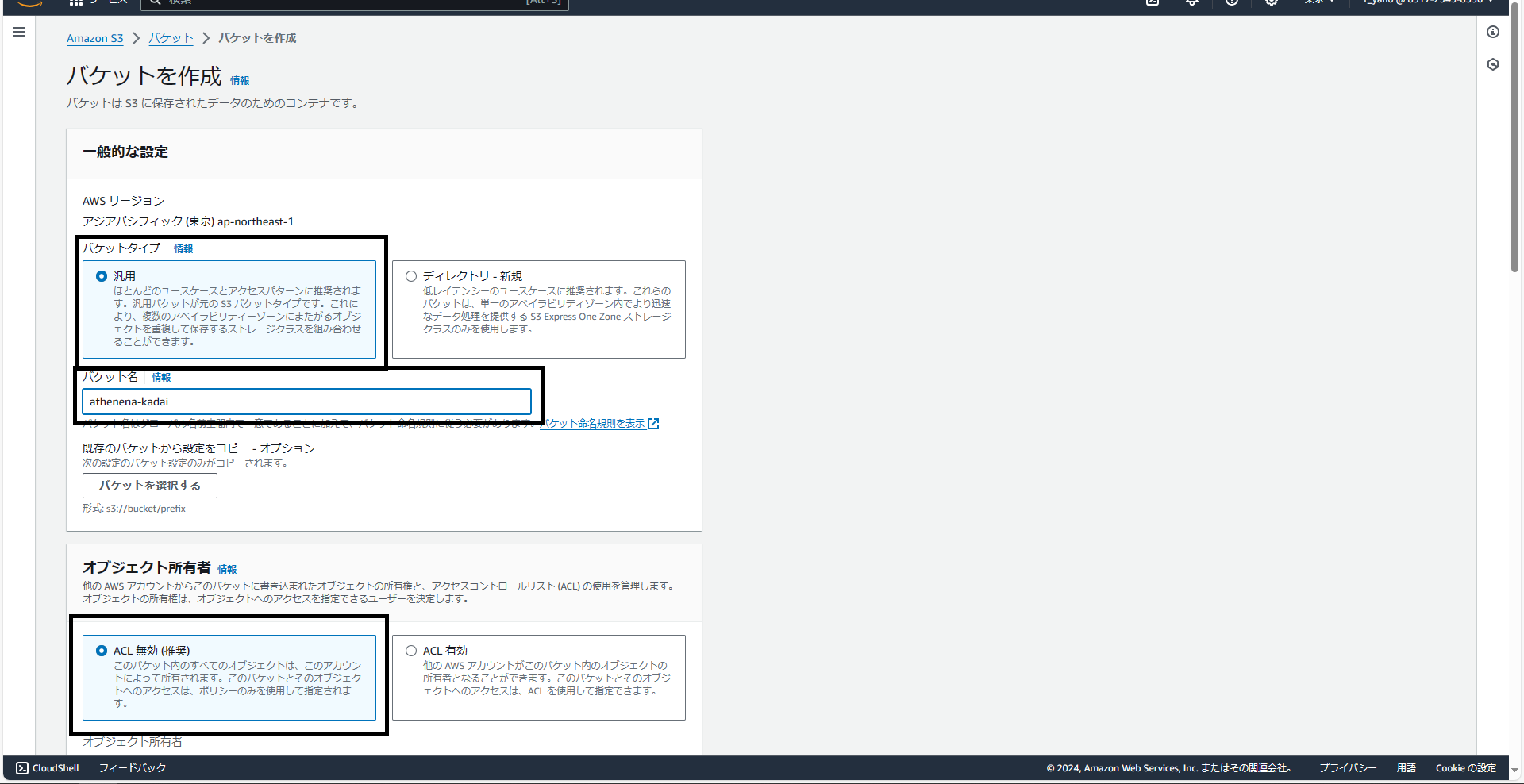
バケットタイプ:汎用タイプ
バケット名:任意
オブジェクトの所有者:ACL無効
今回はバケット名を「athena-kadai」としました。また、S3内のオブジェクトを触るのは今回僕だけの予定なのでACLは無効にしています。
下にスクロールすると下画像の項目が出てきます。
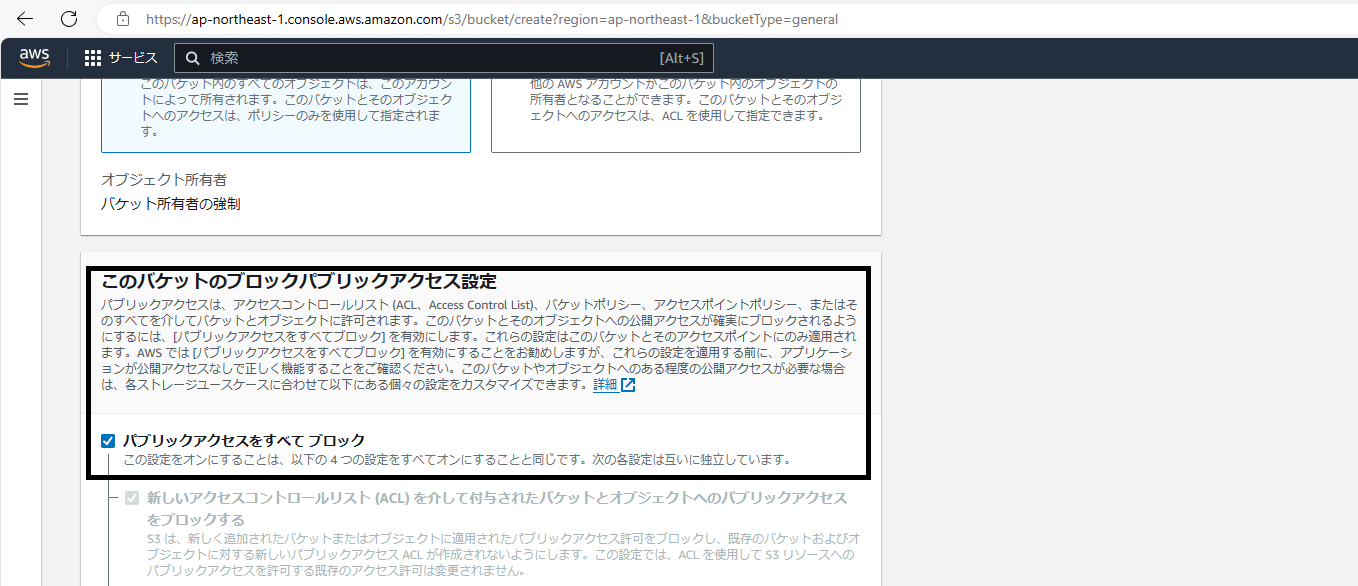
外部からのバケットとその中のオブジェクトへのアクセス権を細かく設定できるみたいですが、前述の通りなので今回もこれは変更せずに進みます。場合にもよりますが基本的にすべてブロックすることが推奨されているみたいです。
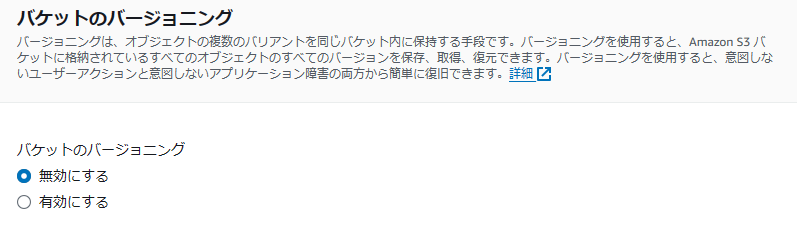
次の項目がバケットのバージョニングの設定です。これは有効化することによって耐障害性(ここではフォールトトレラントの概念)が向上するみたいで、業務で利用する場合などは有効化することが推奨されているそうです。(訳が分からなかったので調べました(笑))
しかし、オブジェクトを上書きする際に課金が発生するらしく、有効化すると不意の課金が怖かったことと、今回は障害が起こってもダメージのない個人的な作業を行うだけなので無効にしました。
あとは、タグのキー値を「Athena」に設定してバケットを作成しました。
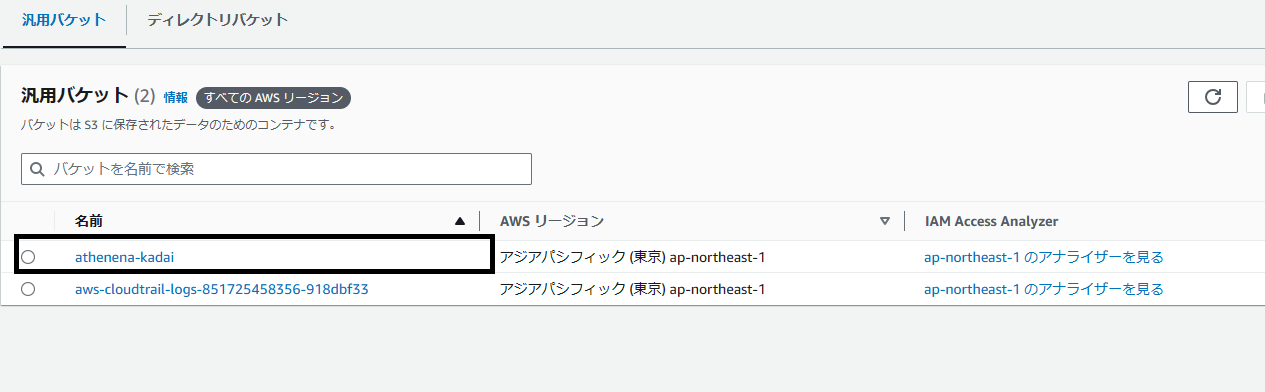
上画像の通りバケットが作成できました。Athenaにてクエリ実行前に、もう一度バケットを作成することになりますが手順はこれと同じだったのでほとんど時間をかけることなく作成できました。
上画像の作成したバケットの「名前」をクリックすると次の画面でデータをアップロードできます。今回はドラッグ&ペーストでできたのでデータをweb上に置くと次の画面に移ります。
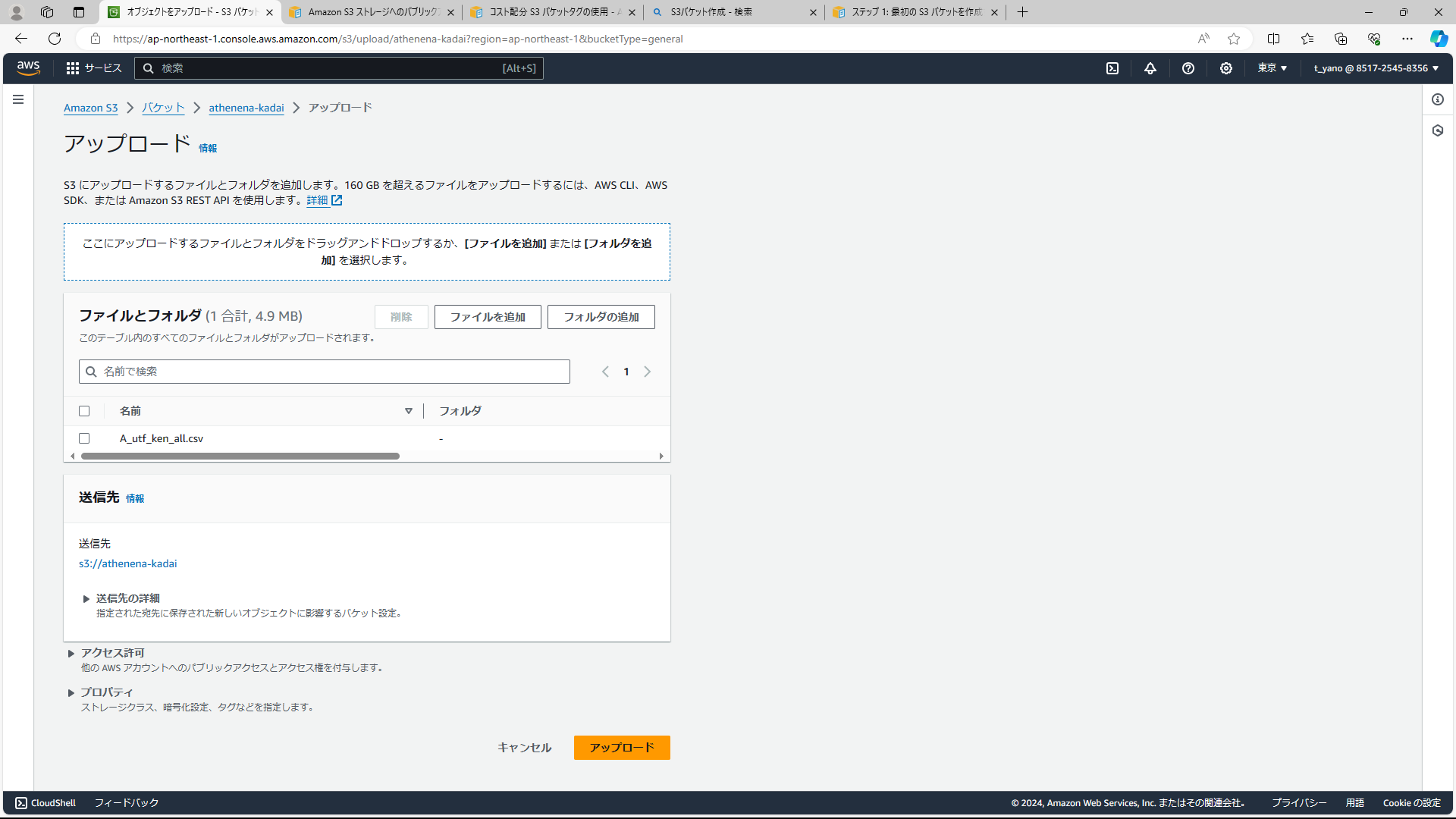
特に設定する項目もなかったのでそのままアップロードして「1.S3バケットの作成」は終了です。
※追記
今回はAとBの2つのCSVファイルを使用するためバケット内に下記のようなフォルダを作成し、そこにアップロードしました。

2.S3のデータからテーブルを作成する
さて、必要なデータをS3に保存できたのでいよいよAthenaに触れていきます!
まずコンソール画面の検索ボックスに「Athena」と入力して移動します。
移動後の画面サイドバーからクエリエディタをクリックします。(下画像)

クリックするとクエリを実行する画面に移動するのでここでテーブルを作成します。
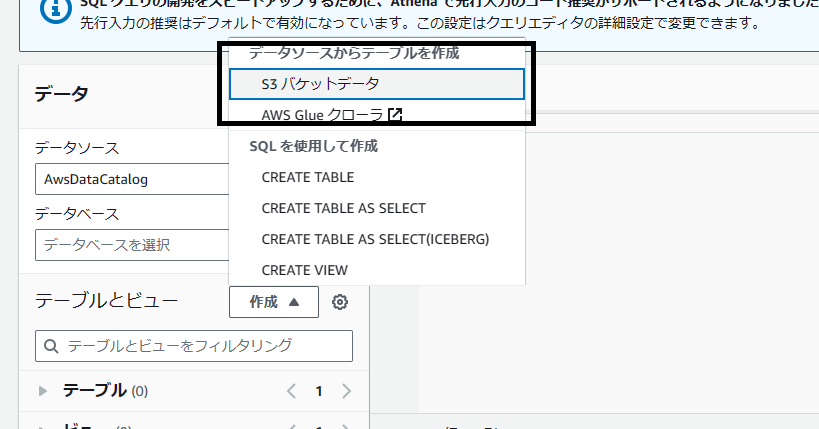
画面左に真ん中あたりに「テーブルとビュー」という項目があるのでその右側にある「作成」をクリックし「S3バケットデータ」を選択します
すると、テーブル作成のための画面に移動するので必要事項を記入していきます。
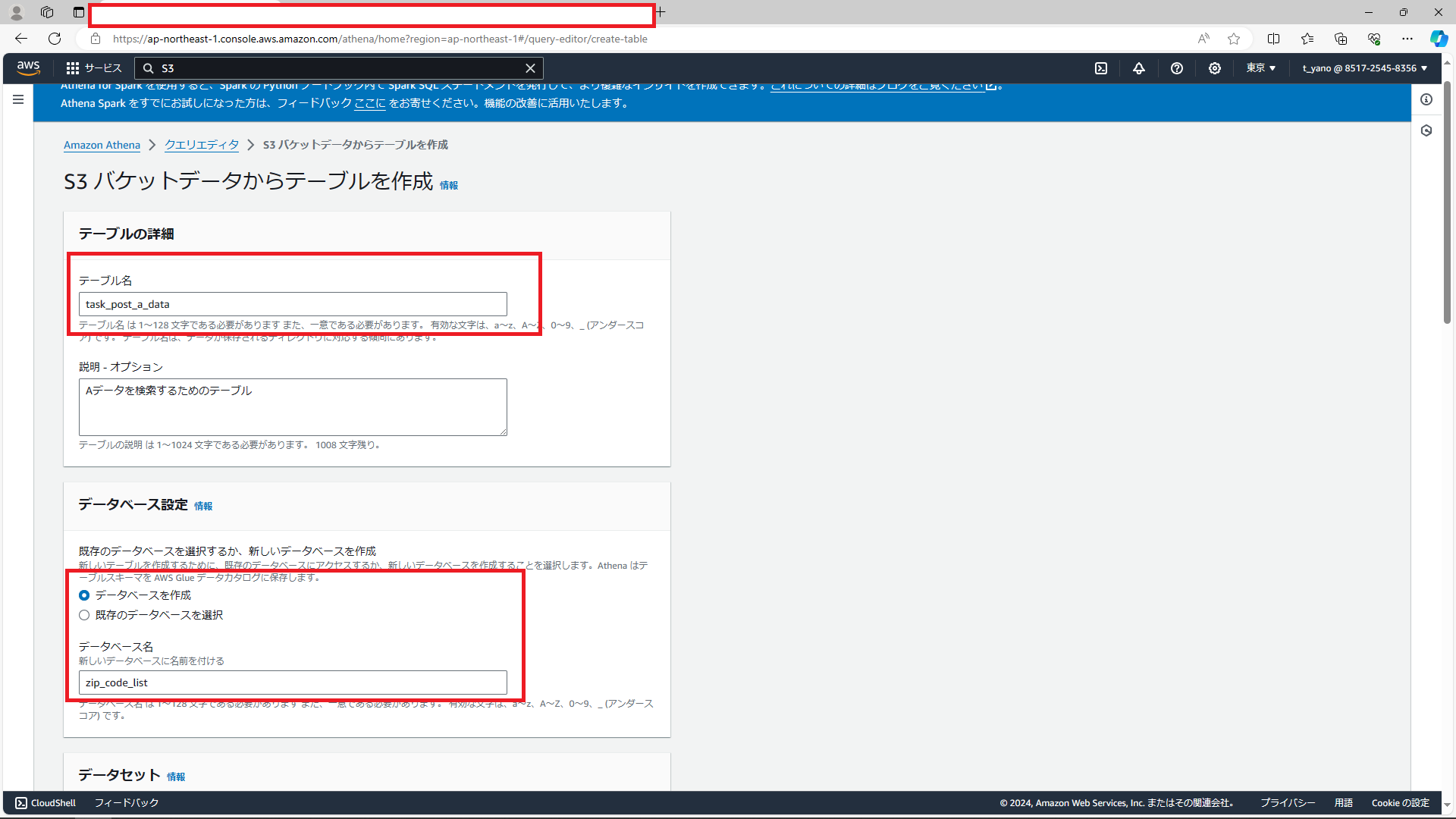

データベース名:任意(今回は既存のデータベースはないのでデータベース作成を選択します。)
データセット:バケット内の任意のフォルダを選択。(「S3を参照から簡単に選択できます。」)
テーブルタイプ:Apache Hive
※Apache Hiveとは「大規模な分析を可能にする分散型のフォールトトレラントなデータウェアハウスシステム」らしい。
ファイル形式:CSV
ここまででテーブル作成時のファイル形式の指定などは終了。下にスクロールすると、テーブルのカラム名と型の指定ができるので下記のように入力。
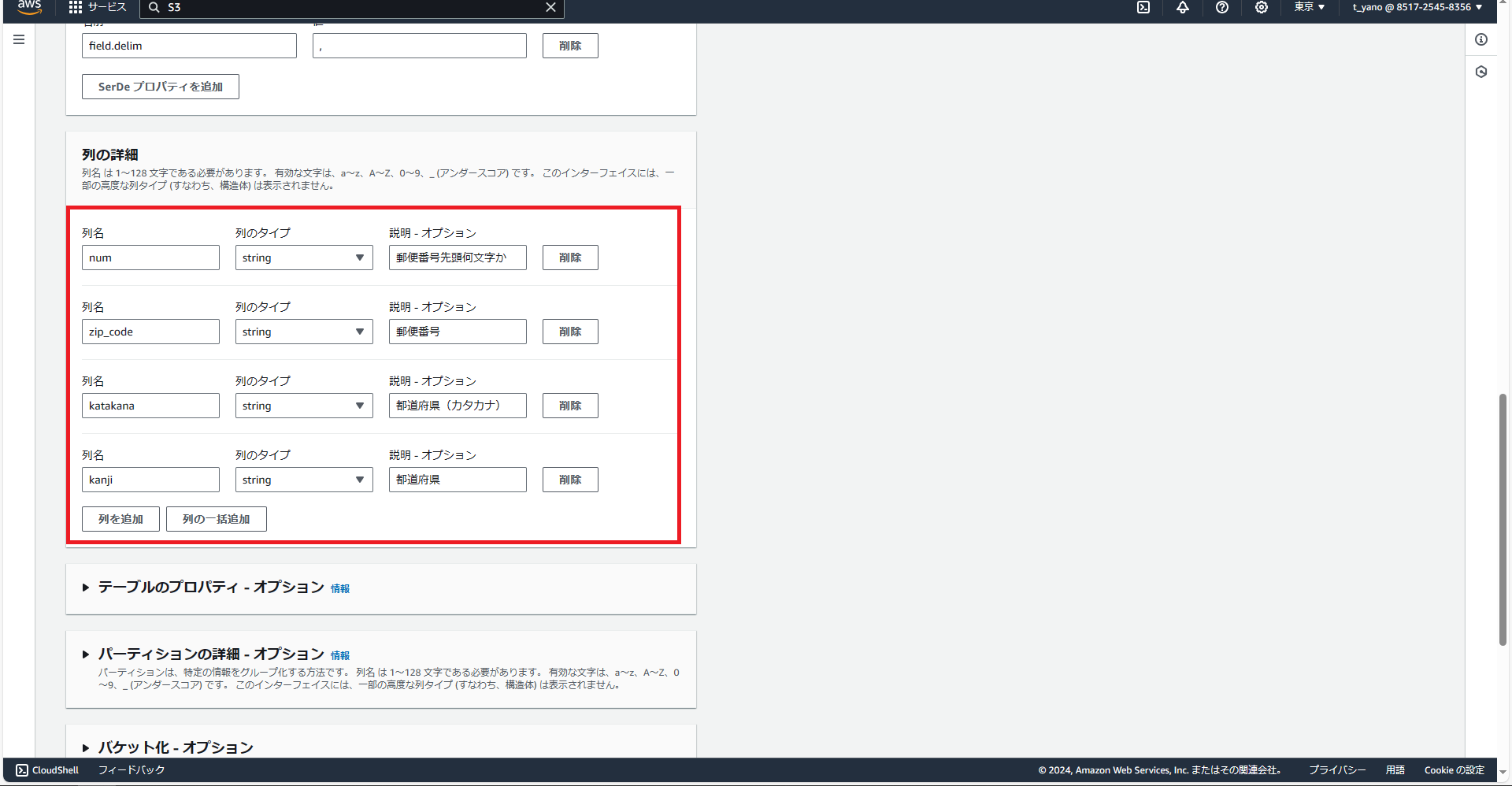
※注意
今回初回作成時にカラム名にローマ字を入れていました。見栄えが悪いのと暗黙の了解的に上記のように英語と「_」を使うことが推奨されているらしいので、皆さんはこんな初歩的な指摘をされないようにカラム名の指定を行ってください。
もう一点。作成時に郵便番号の列をint型で作成してしまいましたが、こうすると1列目の値が正しく出力されませんでした。基本的に型が明示的に明らかな場合以外は「string」型で指定しておくことが良いそうです。ここも注意しましょう。
実行結果が下の画像です。
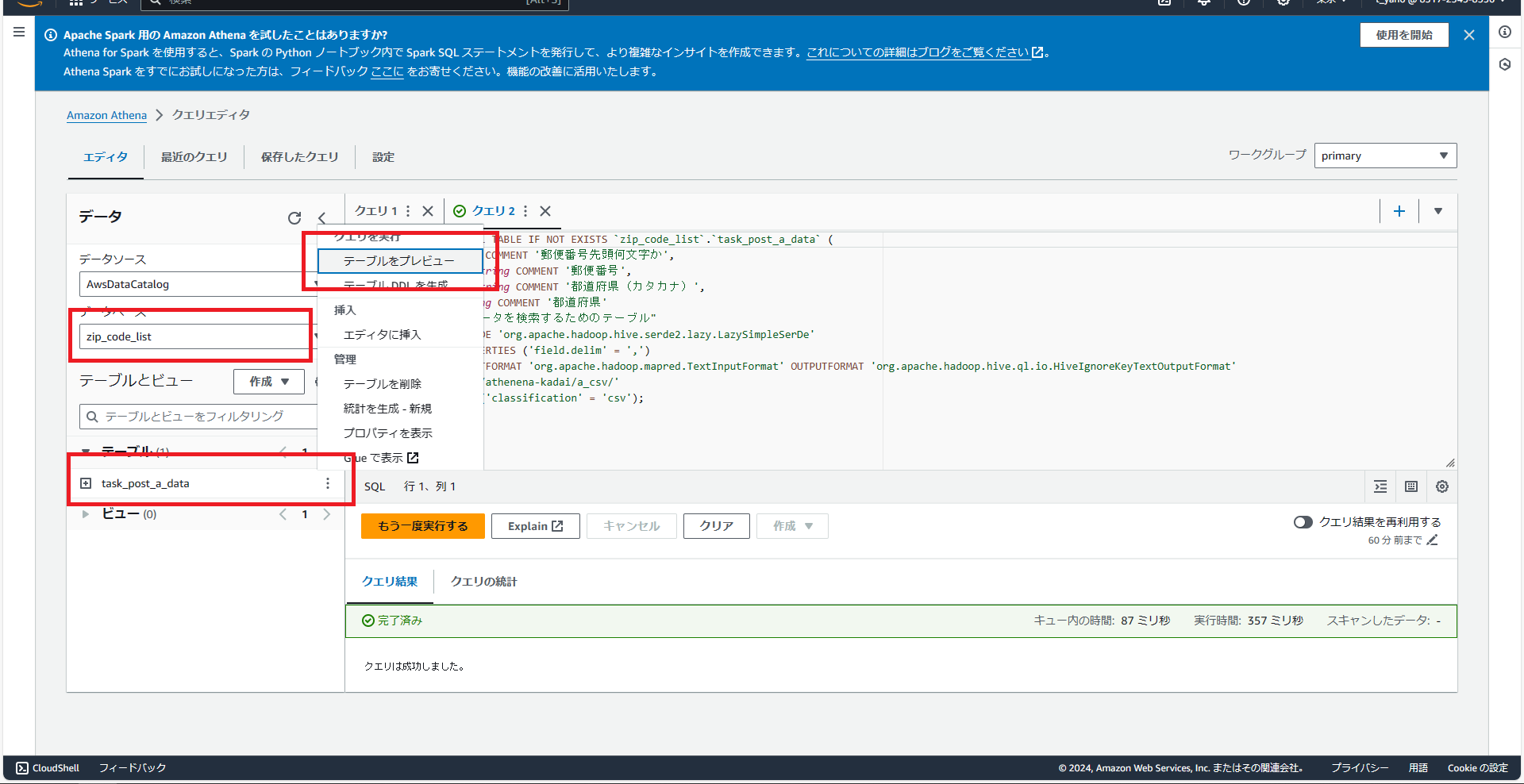
画像の通りデータベースとテーブルが新しく作成されていることがわかるかと思います。ではテーブルの中身を確認するために画像の通りプレビューしてみましょう。
プレビューだと「limit 10」が文末について10行しか出力されないので、文末を消して出力した結果です。
少し画像が荒くなってしまいましたが、テーブルが作成できていることがわかるかと思います。
では、このテーブルを利用していただいている課題通りに検索を行ってみましょう。
Aテーブルに対して行った課題は下の二つです。
Q3:各都道府県毎に幾つの郵便番号が存在するかのリストを作成してください。
Q2:愛媛県にはいくつの郵便番号が存在するか?(GROUP BYとDISTINCT)
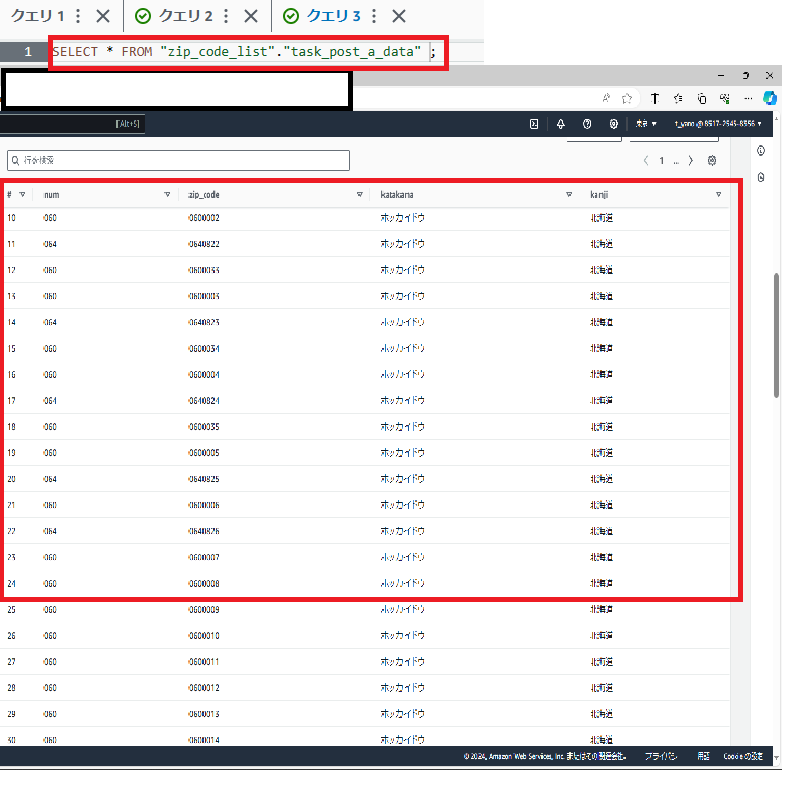
では、まず愛媛県にはいくつの郵便番号が存在するかを検索してみます。特に難しいことはないですが、郵便番号の重複をなくすためにDISTINCTを使用して下記のようにSQL分を実行しました。
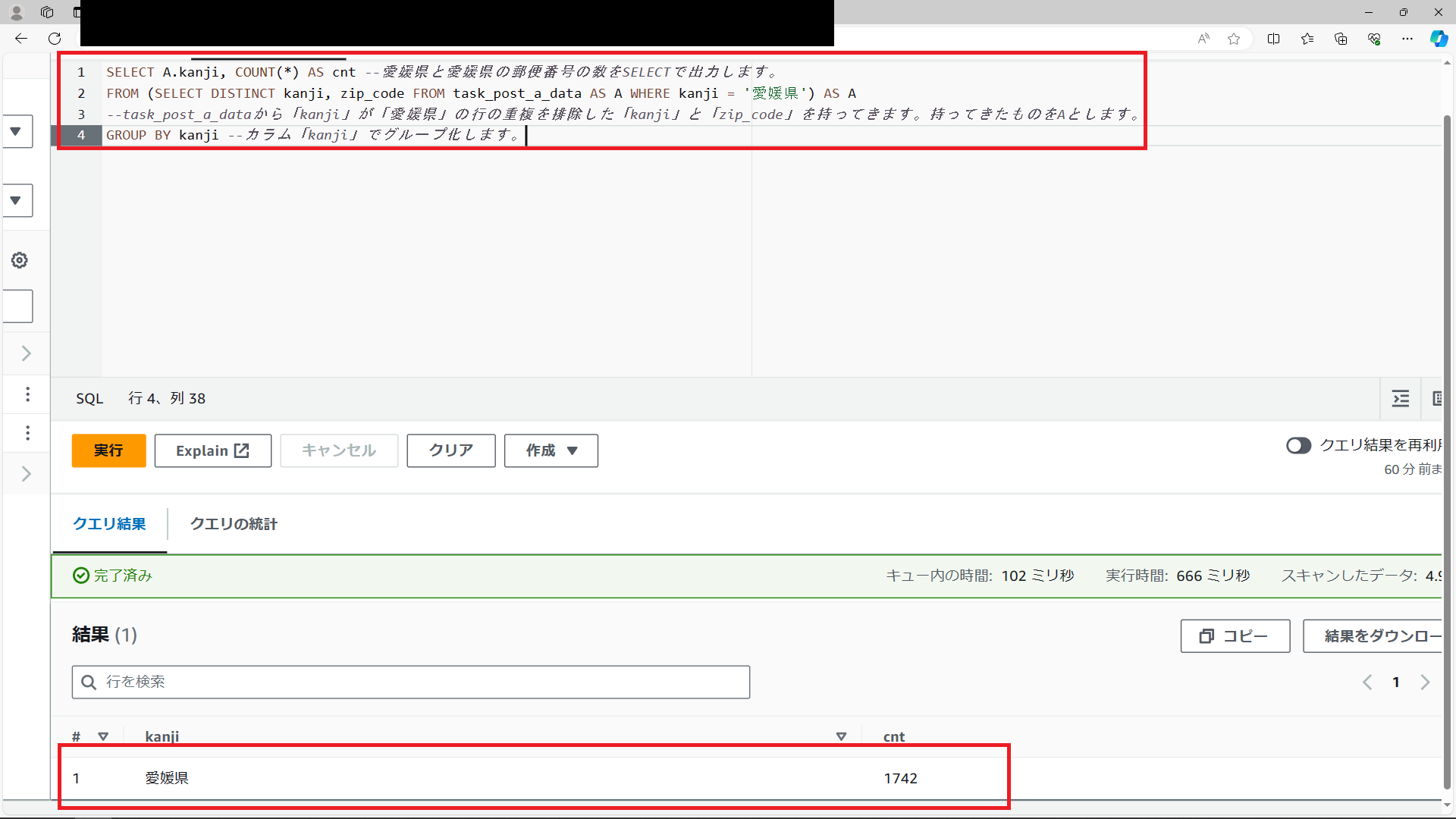
SQL文のコメントに書いてある通りですが、カラム「kanji」でグループ化して愛媛県の郵便番号数をCOUNT句で数えています。
また、重複をなくすために今回はサブクエリを使用し、リストAを作成してFROMの対象をAに指定しています。
結果は1742でした。結構な数あるみたいですね。
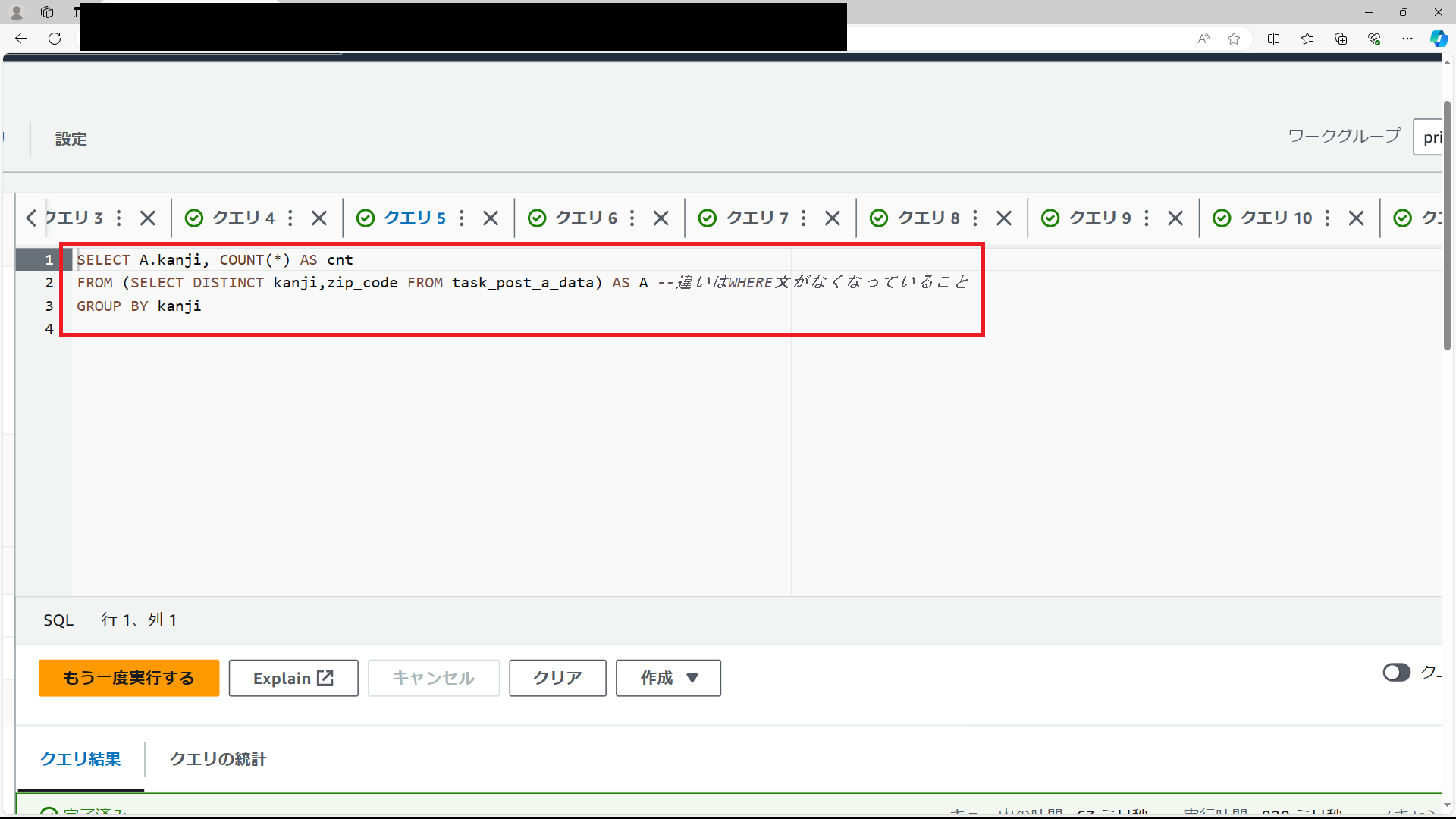
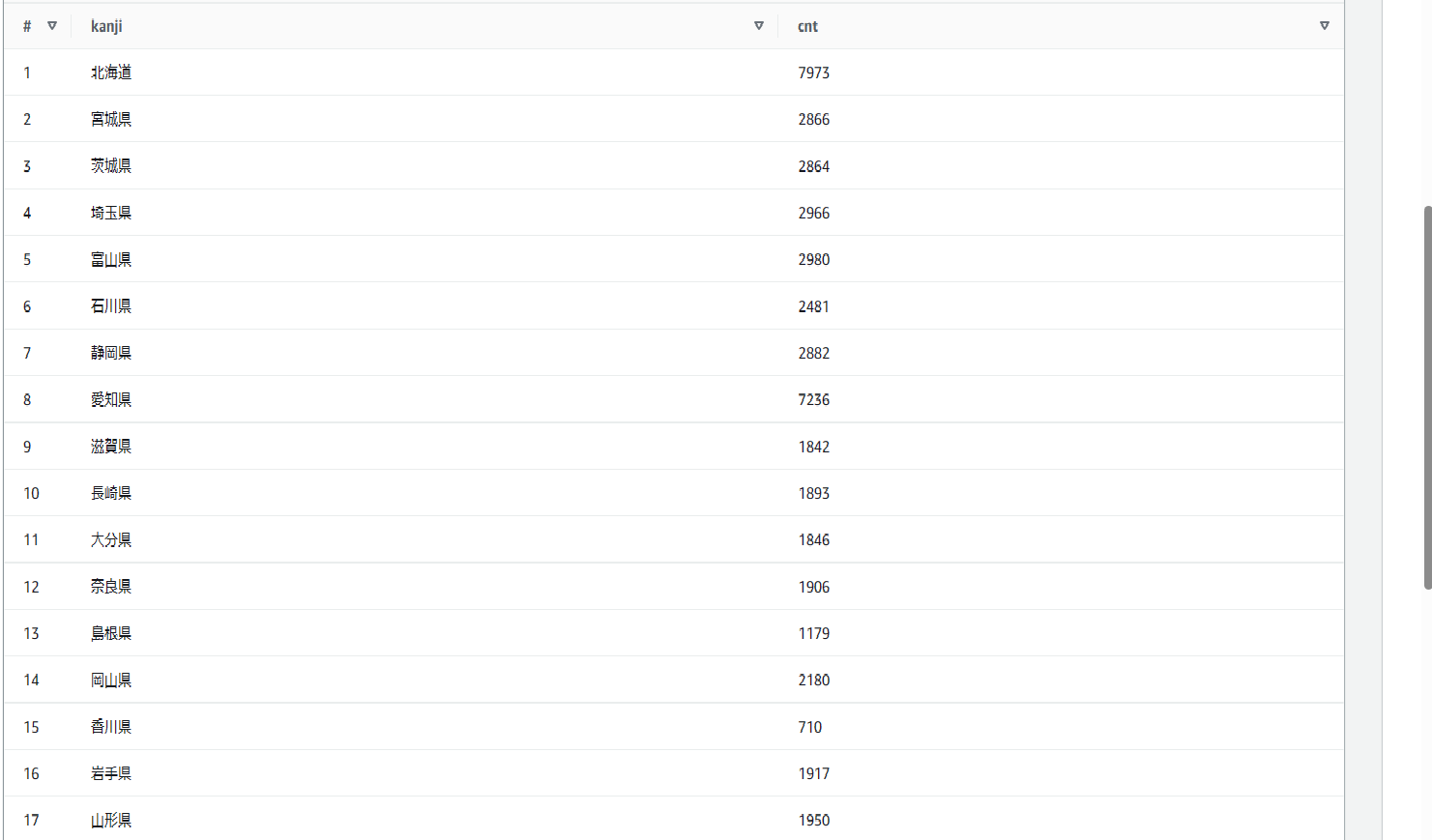
Q3:各都道府県毎に幾つの郵便番号が存在するかのリストを作成する。
この課題はQ2とほとんど同じSQL文で作成できる。下画像のようにWHERE文を外すと「kanji」が「愛媛県」の行という条件がなくなるので重複を省いて47都道府県すべてのリストを表示可能です。
BデータをS3に保存して、新しくテーブルを作成し課題を行う。
テーブルを作成する方法はAテーブルと同様。ですが、今回はAテーブル作成時のクエリを参考にして、クエリに直接書き込む方法で作ってみようと思います。
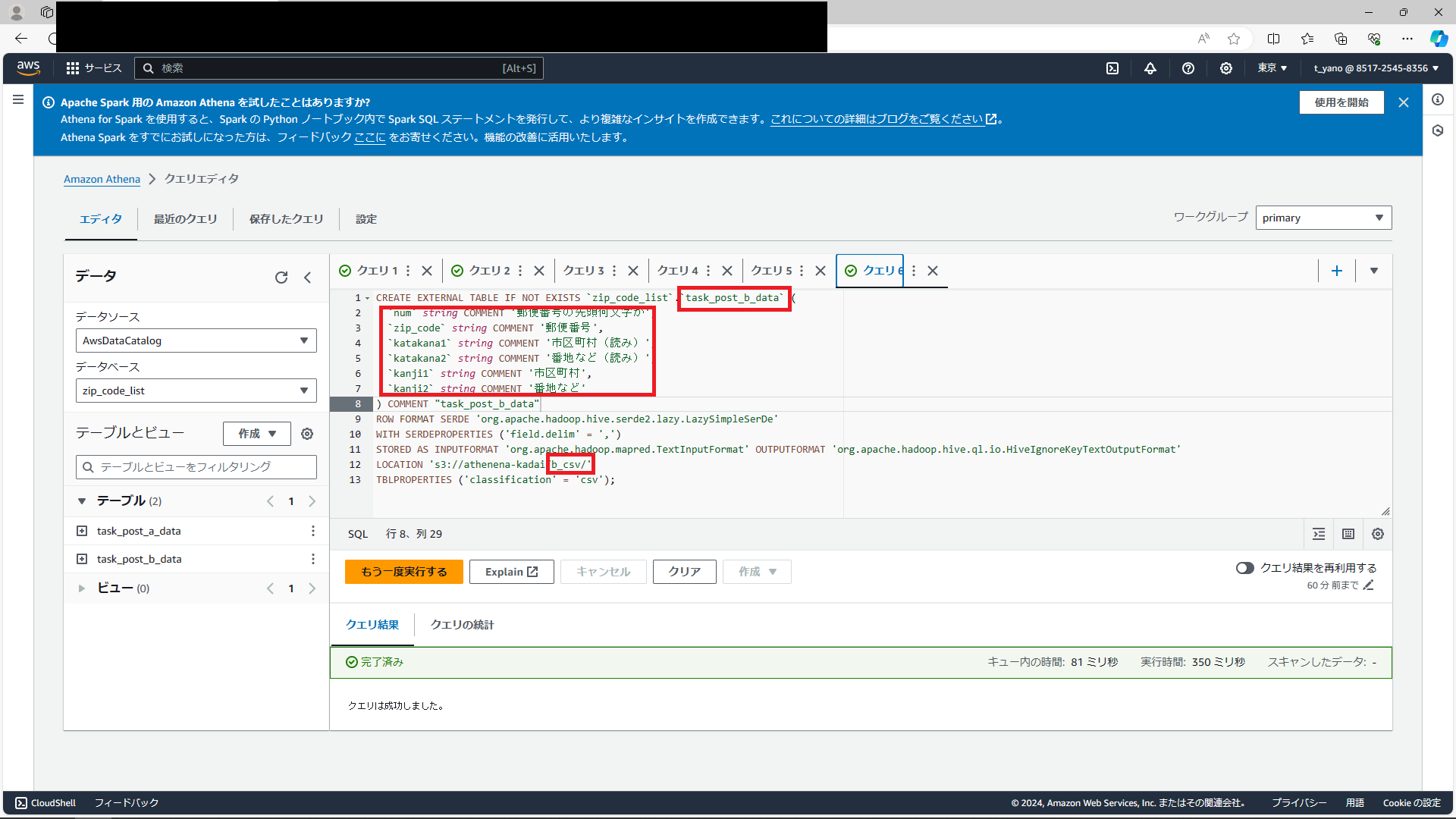
上記画像のようにクエリに書き込みました。赤で囲んだ部分が変更した点です。
作成したテーブルをプレビューしてみましょう
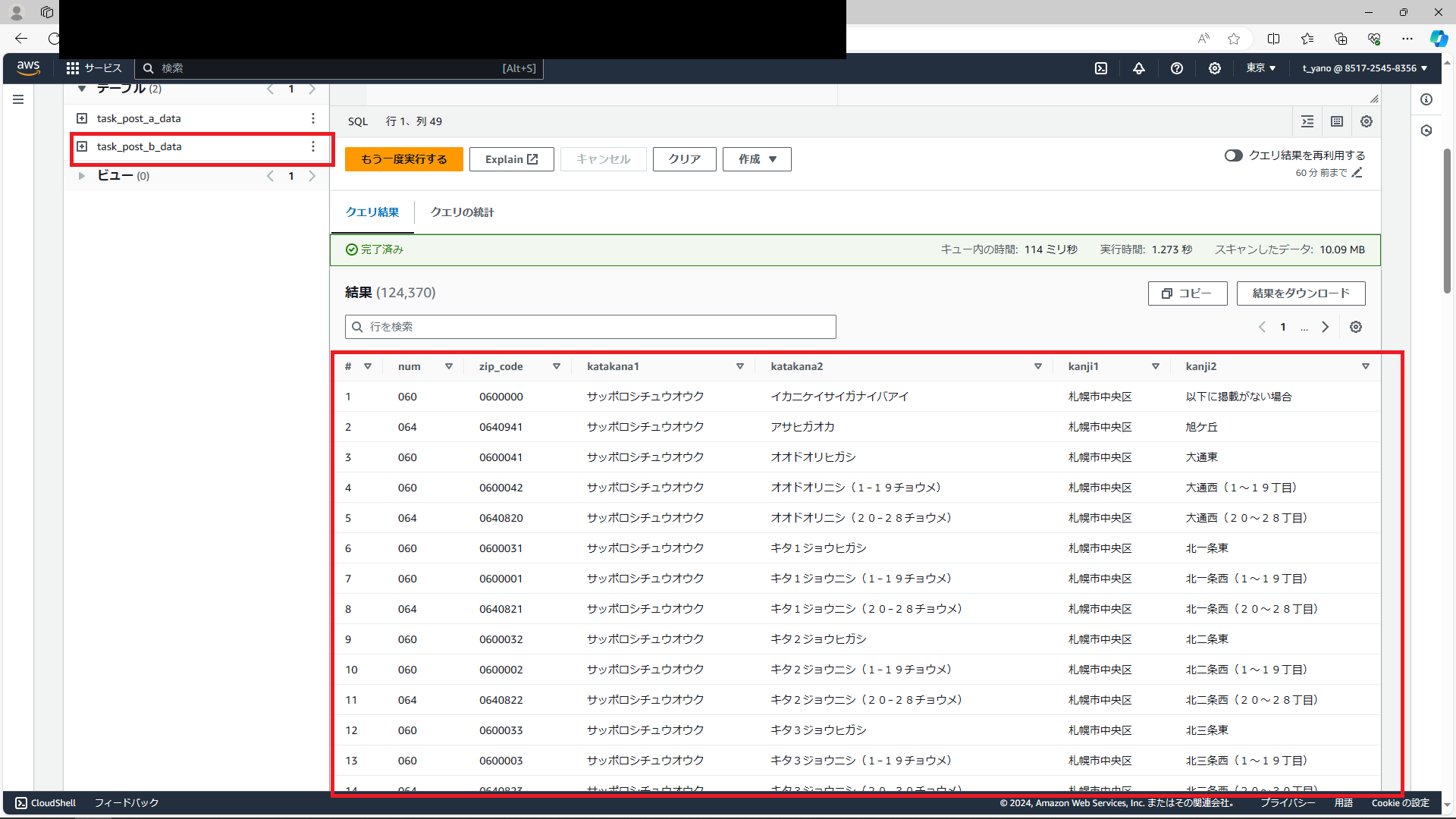
テーブルの作成に成功しているようですね。
では、このテーブルを使って下の課題をやっていきます。
Q6:地名の最終ブロック(地区名)が「泉」である地域は幾つありますか。
Q7:地名の最終ブロック(地区名)に「小泉」が含まれる地域を出力してください。
Q5:「玉城仲村渠」はなんと読みますか?
これは特に難しくもないWHEREを使った検索です。下記のようにクエリを実行すると出てきます。
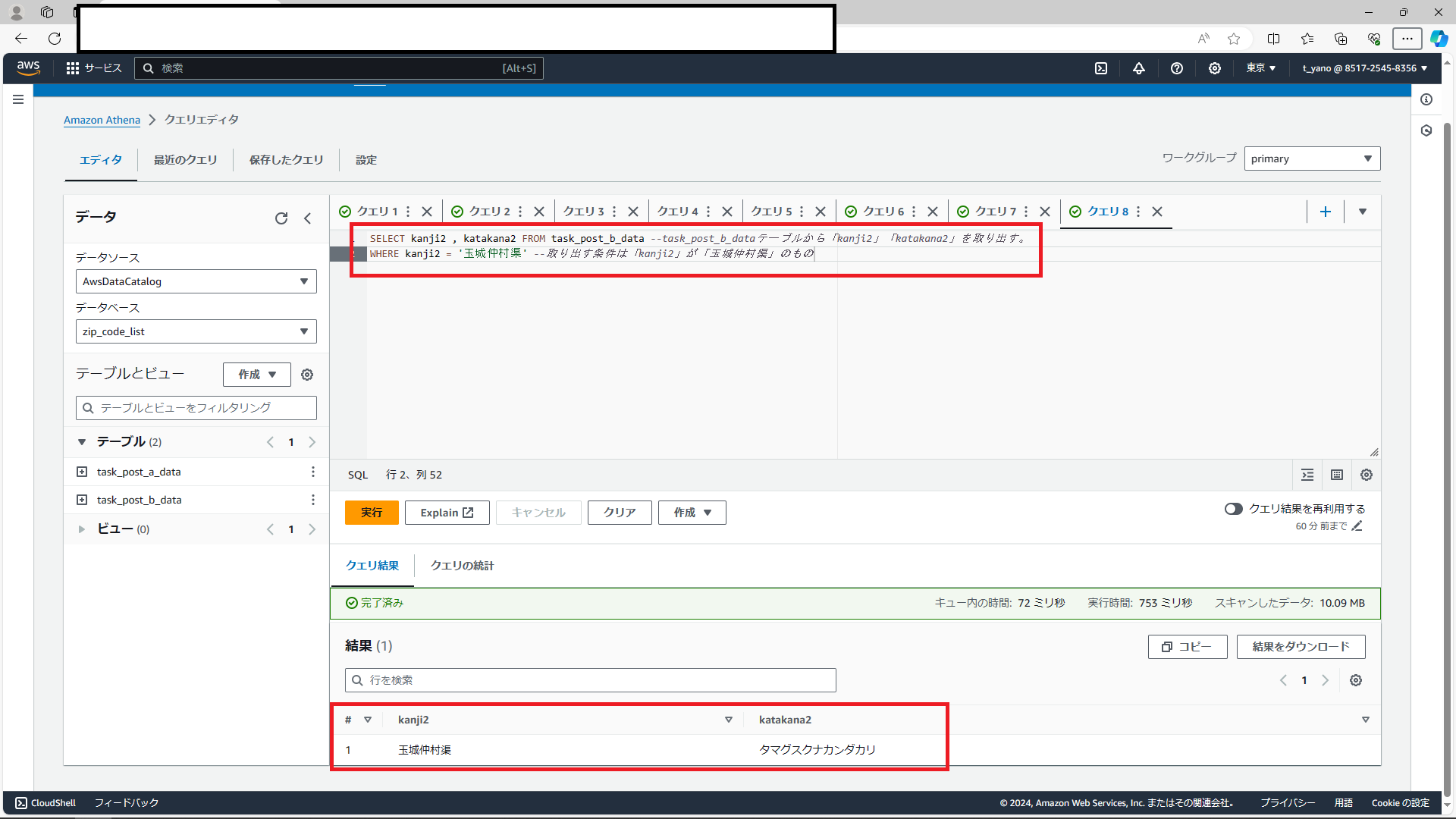
こんな感じに出力されます。これは文章の意味を理解できればすぐにできる問題でした。
Q6:地名の最終ブロック(地区名)が「泉」である地域は幾つありますか。
これもそこまで難しいことはありません。今まで出てきたSQL文だけで記述可能です。

今回はリスト化するカラムに「kanji2」も入れていますが、数だけわかればよいのであれば「COUNT」だけでもよくなります。
その場合、GROUP BY句も必要なくなり、上2行から「KANJI2」を消した文だけでデータを取得できます。
Q7:地名の最終ブロック(地区名)に「小泉」が含まれる地域を出力してください。(LIKE演算子)
一見Q6と同様に見えますが、ここでは「小泉」が含まれていればなんでも良いということです。つまり「南小泉」「小泉北」などパターンは多様です。
このような場合、LIKEを使った曖昧検索を行います。

上画像のようにLIKE演算子を使用する場合は下のような検索方法があります。
後方一致:%〇〇〇
部分一致:%〇〇〇%
※〇〇〇は任意の文字列
このようにすることで「どこかしらに指定の文字を含む文字列」を検索することができます。検索した結果が下画像です。
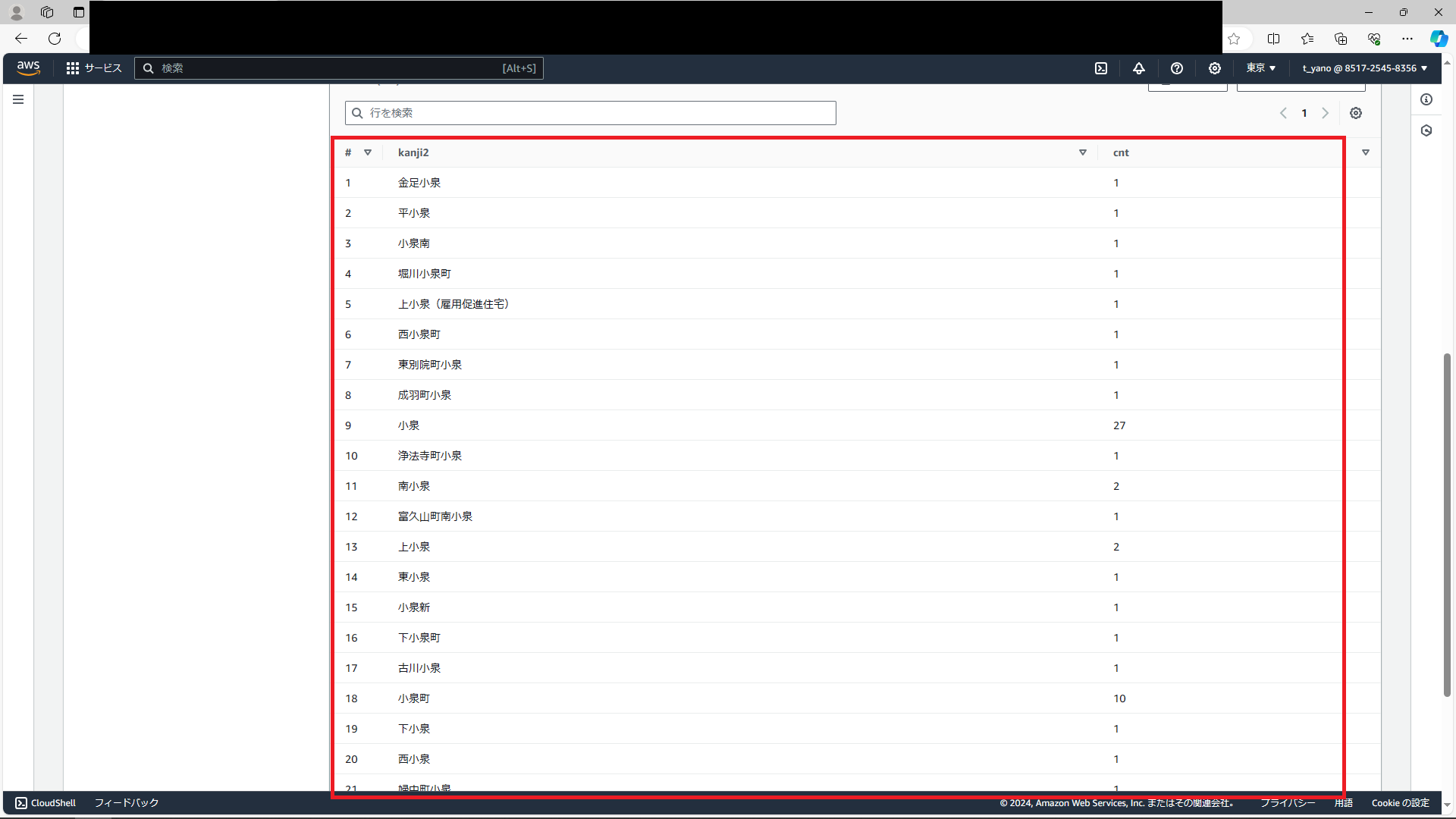
しっかりとほしかった情報が検索できています。
また、今回はCOUNT句で数を数える必要はなかったので「SELECT kanji2 FROM task_post_data WHERE kanji2 LIKE ‘%小泉%’」でもよかったのですが、
この場合27個ある「小泉」はすべて表示されるので今回は「小泉という地名が27個ある」と分かるようなSQL文になっています。
※おまけ(正規表現)
LIKE演算子による「曖昧検索」と似たものに「正規表現による検索」があります。代表的なものを下に記載しておきます。
※[^…]で任意の文字以外の文字を検索できる。
「*」 : 直前の文字の0回以上の繰り返しを表す。例:ap*le =ale,apple,aple,appple等
「+」 : 直前の文字の1回以上の繰り返しを表す。例:ap+le = 上のale以外
「^」 : 直後の文字が対象の先頭にある文字を抽出する。例:^apple = apple,applea,applebye等
「$」 : 直前の文字が対象の末尾にある文字を抽出する。例:apple$ = apple,aapple,iphoneapple等
AテーブルとBテーブルを使って検索する
最後の課題はAテーブルとBテーブルの両方から値を抽出する必要がある課題を行いました。
Q8:地名の最終ブロック(地区名)に「江戸」が含まれる地域について都道府県、市町村、地区名を繋いだでリストを作成する(INNER JOIN)
ここで都道府県はAテーブル、市町村と地区名はBテーブルに存在することを理解しておく。ここで使用したのは内部結合(INNNER JOIN)

上画像のように記述することで両テーブルに存在する「zip_code」を使ってテーブルを結合することができます。
テーブルを結合したうえで条件に合う行を抽出しCONCAT句で指定した複数のカラムを結合したものをリストとして表示します。実行結果は下画像です。
※今回使用した内部結合ではどちらのテーブルにも存在する値の行しか結合できない。片方にしか存在しない行を結合したい場合は外部結合(「LEFT OUTER JOIN」 or 「RIGHE OUTER JOIN」)を使う必要があります。

しっかりと都道府県、市区町村、市区町村以下が結合されて表示されています。
以上で初心者向けAthena課題はすべて終了しました。お疲れさまでした。
かかった費用について
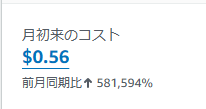
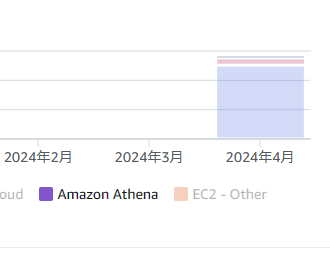
今回かかった費用について参考までに記載しておきます。今月の支払いは0.56USD(約85円)でしたが、下画像を見てもらえばわかる通りほとんど別作業時にRoute53を使用した際の金額です。
つまりAthenaにかかった金額はそれほど多くないということがわかるかと思います。
ただ、ここで考えないといけないのはまだS3は無料利用枠の対象内で実行できていたという事実です。下画像見てもらえればわかるようにもうほとんど使い切っているのがわかるかと思います。

私も詳しくAWSの料金体系を理解しているわけではないので今回使用したAthenaとS3の料金体系を確認できるサイトと、今回無料利用枠を超過しそうなPutリクエストについての説明ページを下記に残しておきます。
・Athena料金体系
・S3料金体系
・S3(putリクエストについて)
終わりに
今回はAthenaを使ったデータ分析の初歩レベルを実践した結果を書かせてもらいました。取り掛かってみればかなり面白い内容で、データ分析という今後も必要になるであろう技術を学べることは自分の糧になると感じました。
皆さんもお暇な時間にぜひAthenaに触れてみてはいかがでしょうか?


コメント