

フェイス・ソリューション・テクノロジーズ株式会社 IS 本部 OS ユニットの masです。
今回はAmazon Athenaのパーティションについての解説と実際に使用する手順についてご紹介したいと思います。
こちらは、コスト削減やパフォーマンス向上の観点から必要になる機能ですのでちょっと馴染みにくいかもしれませんが、きちんと理解しておきたい内容です。
パーティションの解説
Amazon Athenaのパーティションとは
まずパーティションってなに?ってなると思います。
簡単に言うとインデックスみたいなものなんですが、わからない方もいらっしゃるかもしれないので下記のように図にしてみました。
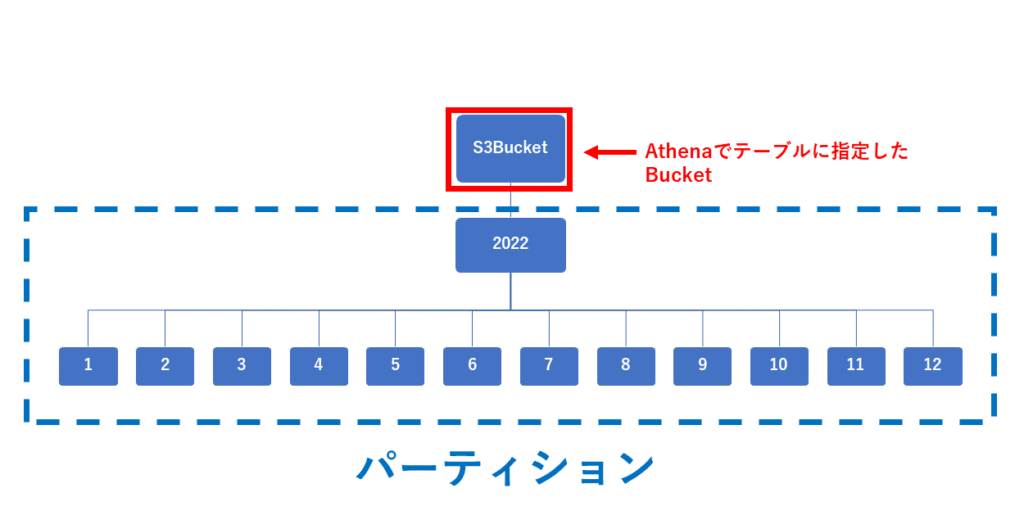
Athenaでテーブルに指定しているS3Bucketを、年や月毎のフォルダに区切っている状態がパーティション化している状態です。
月毎に分けてもフォルダ内のデータ量が大きくなってしまう場合には毎日、毎時、毎秒と区切ることでより細かくパーティション化できます。
あまり難しく考えず、単純にS3をフォルダ分けしていればパーティション化されていると考えても大丈夫かと思います。
なお、S3のパーティション化に加えて、テーブル作成時のDDLにもパーティションの設定を書き加える必要がありますので、そちらは後ほど紹介します。
テーブルに指定されているS3Bucketってどういうこと?って感じの方はAmazon Athenaの基本的な操作方法等について以前の記事で解説しておりますので、是非一度ご覧ください。

どんなメリットがあるのか
コスト削減とパフォーマンス(検索速度)が向上します。
その理由は、パーティションのキーを条件にして絞り込んで検索すると、条件に当てはまらなかったフォルダを検索しなくなる為です。
例えば、先ほどの図のようにパーティション化したテーブルで2022年3月のデータを絞り込んで検索すると、以下の図に赤線で示したように3月のデータだけを検索して、他のフォルダのデータは検索しなくなります。
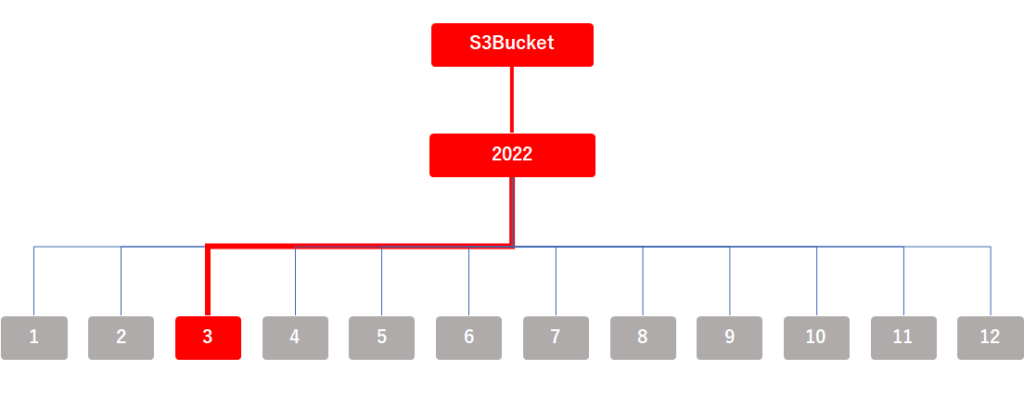
絞り込んだフォルダのデータしか検索されなくなるので、検索するデータ量が少なくなり、検索にかかる時間とコスト(料金)が削減されます。
パーティションの分け方は2種類
パーティション分けするフォルダの名前の付け方によって「Hive形式」と「Hiveじゃない形式」の2種類に分かれます。
まず、Hive形式ってなんだろう?ってなると思いますが、今のところは深く考えずにフォルダ名が以下のようになっているパーティションがHive形式になっていると思ってください。
s3://log/year=2021/month=01/day=26/「year=○○」みたいにフォルダ名が「key=value」の形になっていたらHive形式のパーティションです。
ちょっと変わり種で「dt=2022-12-01」みたいなのもHive形式になります。
ちなみに「Hiveじゃない形式」は以下のような形式でパーティション化したものです。
ご覧の通りHive形式とは違いフォルダ名が「key=value」の形で書かれていません。
s3://log/2021/01/26/「Hive形式」と「Hiveじゃない形式」の違い
「Hive形式」と「Hiveじゃない形式」ではテーブル作成時のコマンド等が違ってきます。
しかし、それより重要な相違点がありまして、「Hive形式」の場合だと、パーティション(フォルダ)が追加される度にテーブルの再読み込みを実行してあげないと追加されたパーティションを検索できません。
「Hiveじゃない形式」の場合はその必要がないので、日々、或いは月々、年々と時間経過毎にパーティションが増えていくような場合は「Hiveじゃない形式」でテーブルを作成した方が良いです。
それでは今回は「Hiveじゃない形式」でのパーティションの設定方法について手順をご紹介したいと思います。
パーティションの設定手順
検索するデータを準備する
既にパーティション形式で保存されているデータをお持ちの場合はこちらの手順は省略していただいて結構です。
とりあえず試してみたいけど、よさげなデータを持ってないという方はご参考ください。
今回は試しにitem_1.csvとitem_2.csvの2つのCSVファイルだけ使用します。
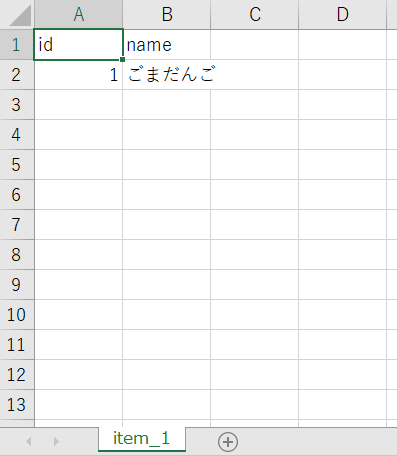
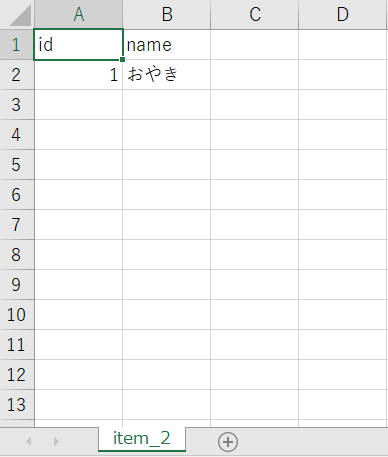
試しに以下のようにパーティション化していないS3バケットにCSVを配置してみます。

この状態で全データを出力させてみると以下のように出力されます。
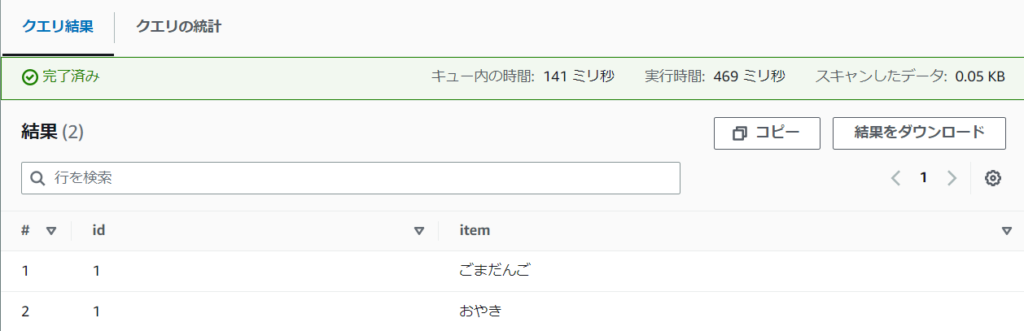
ちなみにこの時にスキャンされたデータ量は0.05KBとなっております。
あまり大きくはないのですが、パーティションを設定することでこれが変化します。
それではS3Bucketをパーティション化してみましょう。
bucketをパーティションに区切る

パーティション化するS3内でフォルダの作成をクリック
「2022」という名前でフォルダを作成
上記の要領で「2022」フォルダの中に「12」フォルダを作成
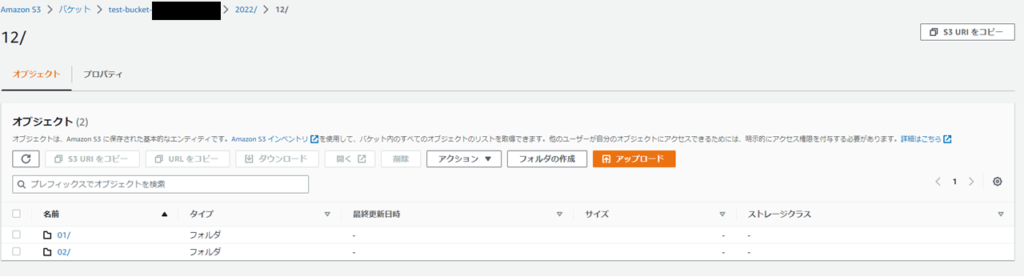
これで下記の2つのパーティション構成ができました。
2022/12/01
2022/12/02それぞれのフォルダに用意しておいたcsvを以下の通りアップロードします。
「2022/12/01」へ「item_1.csv」をアップロード
「2022/12/02」へ「item_2.csv」をアップロード
テーブルの作成
DDLの実行
前回の記事でテーブルの設定手順はご紹介しておりますので、今回は作成用のDDLのみ記載します。
なお、<対象のbucket名>のところはご自身の環境に置き換えてください。
テーブル作成用のDDL
CREATE EXTERNAL TABLE IF NOT EXISTS test(
`ID` STRING,
`ITEM` STRING
)
PARTITIONED BY (
year INT,
month INT,
day INT
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES ( 'escapeChar'='\\', 'quoteChar'='\"', 'integerization.format' = ',', 'field.delim' = ',' )
LOCATION 's3://<対象のbucket名>/'
TBLPROPERTIES (
'classification'='csv',
'skip.header.line.count'='1',
'projection.enabled' = 'true',
'projection.year.type' = 'integer',
'projection.year.range' = '2021,2100',
'projection.year.digits' = '4',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2',
'storage.location.template' = 's3://<対象のbucket名>${year}/${month}/${day}'
)DDL解説
上記DDLにおいて、パーティションの設定をしている箇所について説明します。
まず以下の部分です。
PARTITIONED BY (
year INT,
month INT,
day INT
)ここでパーティションに用いられるキーを宣言しています。
今回は年/月/日の形でパーティションするので上記のようになっています。
続いて、それぞれのキーについて設定している箇所が以下の部分です。
'projection.year.type' = 'integer',
'projection.year.range' = '2021,2100',
'projection.year.digits' = '4',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2', それぞれ以下のような設定項目になっています。
.type: キーの型
.range: 2021 ~ 2100のような数値の範囲
.digits: キーに入る値の桁数
最後に以下の部分が、上記のキーを用いて、実際のS3Bucketをどのようにパーティション化してあるか書き示している箇所になります。
'storage.location.template' = 's3://<対象のbucket名>${year}/${month}/${day}'検索してみる
下記のクエリを実行します。
SELECT * FROM test WHERE year = 2022 AND month = 12 AND day = 01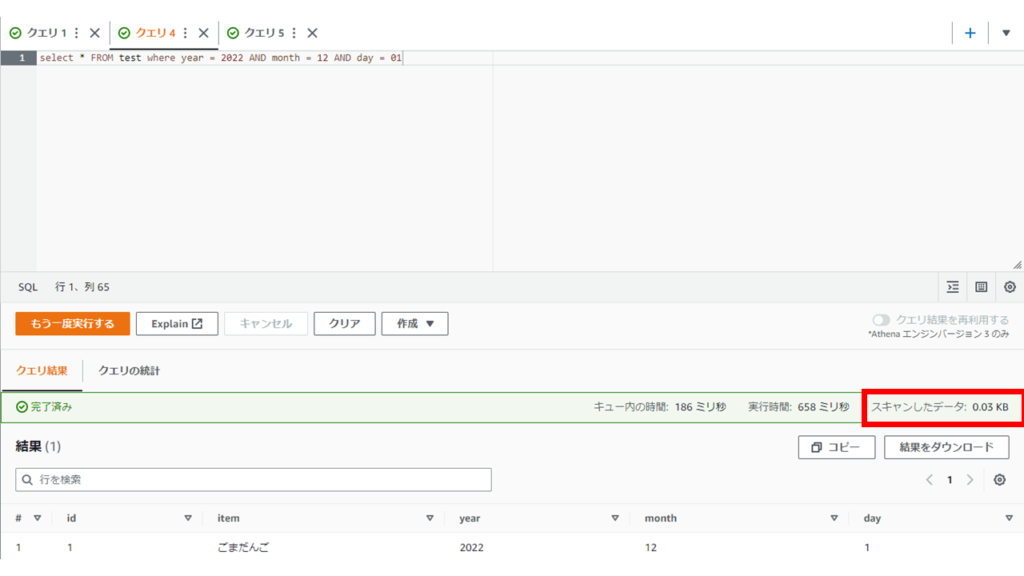
実際に2022/12/01を条件にして絞り込んで検索をかけるとスキャンしたデータがitem_1.csvのみのデータ量になっています。
ちょっとサンプルデータが小さすぎて分かりづらいですが、パーティション化前のスキャンしたデータは0.05KBだったので、ちゃんとパーティションしたデータだけ検索できているようです。
最後に
今回はAmazon Athenaを使用するうえで重要になるパーティションについて解説しました。
検索する度に不要なコストをかけてしまう可能性があるので、パーティションについて十分に理解してきちんと活用できるようにしたいですね。

コメント