

フェイス・ソリューション・テクノロジーズ株式会社 IS 本部 OS ユニットの masです。
Amazon Athenaでは正規表現を使ってデータを抽出し、テーブルを作成することができます。
今回はその方法についてご紹介したいと思います。
なお、実際に正規表現を使ってテーブルを作成するにはDDLの記述方法以外にも正規表現の記述方法を理解する必要があります。
今回はあくまでAmazon Athenaの機能のご紹介の為、具体的な正規表現の解説は割愛しますので予めご了承ください。
概要説明
正規表現を用いたテーブルの作成とは?
例えば以下のようにカンマで区切られたデータ(CSV)があるとします。
id,name,age,like
1,山田,15,ステーキ
2,佐藤,16,カレーおそらく上記のようなCSVからテーブルを作成することが一般的だと思います。
CSVからテーブルを作成する場合は、テーブルを作成するDDLに「OpenCSVSerde」等のCSV読み込み用のSerDe(サーディー)を記述します。
具体的なCSV読み込み用のDDLの記述については以前の記事でもご紹介しておりますので、気になる方は以下の記事をご参照ください。

DDLを実行すると以下の画像のようなテーブルが作成されます。
ご覧の通り、元々カンマがあった位置でデータが区切られていることがわかるかと思います。
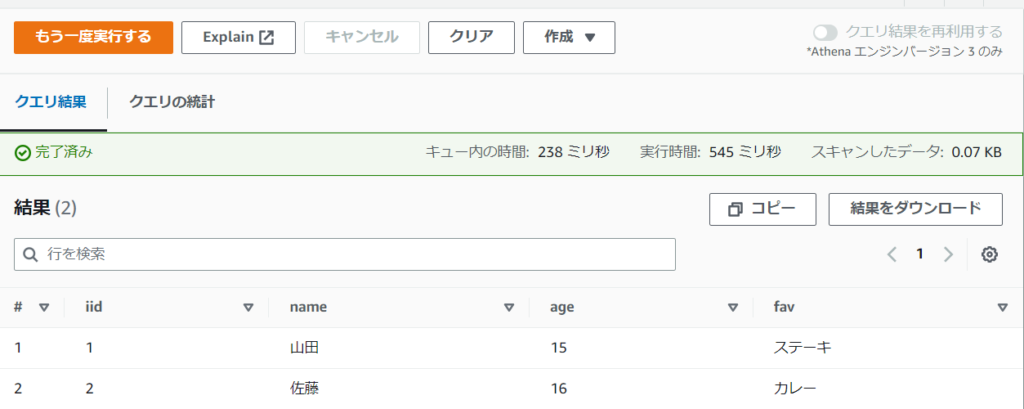
テーブルの元になるデータがCSVだった場合は、元データの見た目からでも、区切られている場所がわかりやすいですね。
しかし、元データが以下のような形式だった場合はどうでしょうか。
1番の名前は山田です。15歳でステーキが好き
2番の名前は佐藤です。16歳でカレーが好き上記のデータから、番号・名前・年齢・好きな食べ物を抜き取ってテーブルを作成しようと考えた場合、文章で書いてあるので、データを抽出するのはちょっと無理そうな気がしてきます。
しかし、上記のデータは書き方に法則性があるので、正規表現を用いて必要なデータだけを抽出することができます。
その結果、CSVから作成したテーブルと同じようなテーブルを作成することが可能です。
どうすれば正規表現を使えるのか?
テーブル作成用のDDLにて、SerDe(サーディー)を「org.apache.hadoop.hive.serde2.RegexSerDe」で指定します。
その後、SerDeのプロパティでデータ抽出用の正規表現を設定します。
SerDe(サーディー)って何?
シリアライザー/デシリアライザーの略です。
シリアライズとは1行分のデータをデータベースに取り込めるように,(カンマ)やタブなどの区切りで
まとまり毎に分割していくことらしいです。
とりあえず、データベースに取り込むために「元のデータを区切ってくれる機能」くらいの理解でいいんじゃないかなと思います。
実際にやってみよう
正規表現を用いたテーブル作成の実験
今回は下記のサイトから郵便番号一覧のデータをお借りして、対象のデータから郵便番号の上3桁と下4桁を別々のデータとして取得してみようと思います。

上記の過去記事でテーブルの設定手順もご紹介しておりますので、今回はテーブル作成用のDDLのみ記載します。
なお、<対象のbucket名>のところはご自身の環境に置き換えてください。
まずは以下のDDLでデータ区切らないで取り込んでみようと思います。
DDL(正規表現を用いない場合)
CREATE EXTERNAL TABLE IF NOT EXISTS post_numbers(
`data` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(.+)"
)
LOCATION 's3://<対象のbucket名>/'こちらを検索してみると以下のような結果になりました。
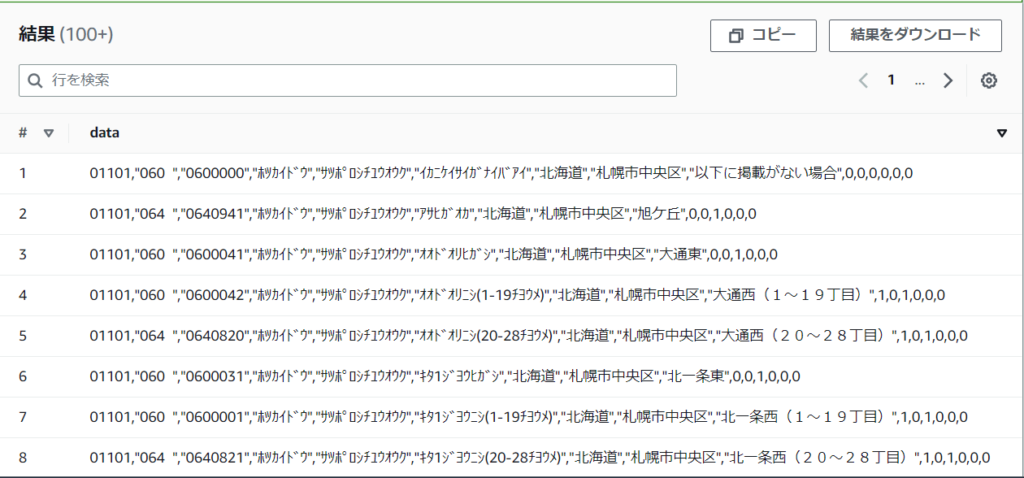
dataのカラムに1行分のデータがそのまま入った状態になっています。
ここから同じデータを使って郵便番号の上3桁と下4桁を別々に抜き出したテーブルを作成してみましょう。
以下が、実行するDDLです。
DDL(正規表現を用いた場合)
CREATE EXTERNAL TABLE IF NOT EXISTS post_numbers2(
`post_number_head` STRING,
`post_number_bottom` STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'input.regex' = '.+,"([0-9]{3})([0-9]{4})",.+'
)
LOCATION 's3://<対象のbucket名>/' DDL解説
以下の箇所で正規表現を使用できるSerDeを指定しています。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'以下の箇所で使用する正規表現のパターンを設定しています。
WITH SERDEPROPERTIES (
'input.regex' = '.+,"([0-9]{3})([0-9]{4})",.+'
)上記のDDLで作成したテーブルを検索した結果は以下のようになります。
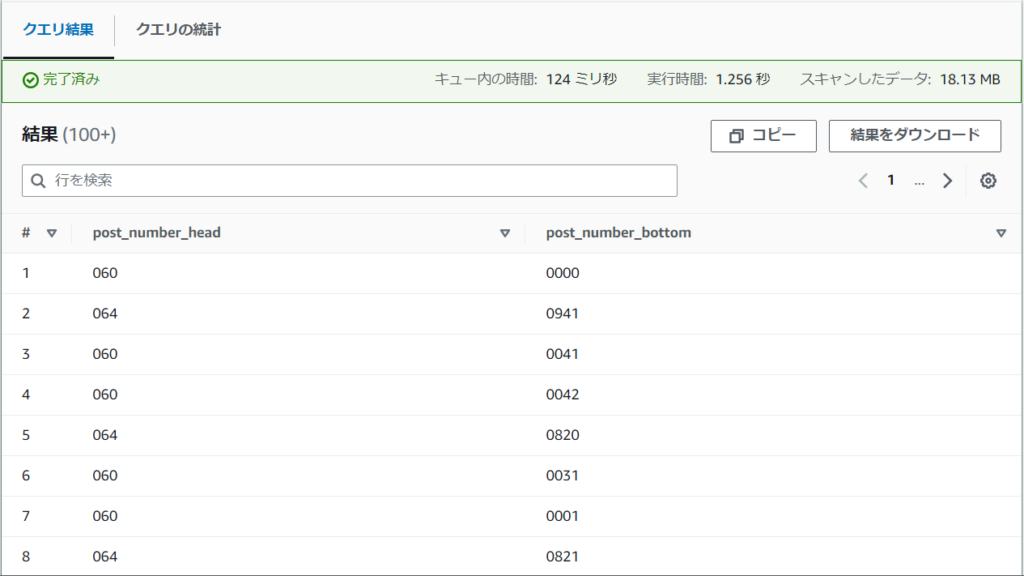
正規表現で上3桁と下4桁を別々に抽出したテーブルを作成できていることがわかるかと思います。
最後に
RegexSerDeを用いることでCSV等のような予め区切られた状態になっているデータではなくても、必要な情報だけを抽出してテーブルを作成できることがわかりました。
正規表現は使いこなすことは難しいですが、取り扱えるデータの幅が広くなるのでぜひ活用していきたいですね。

コメント