
フェイス・ソリューション・テクノロジーズ株式会社IS本部OSユニットのimaiです。
今回はLambdaのS3トリガーで、PDFからテキストを取得してみました。
外部ライブラリのインストール
PDFのテキストを取得するために、pypdfを使用します。
「python」という名前のディレクトリにpypdfをインストールします。
pip install pypdf -t ./python --no-user次に「python」ディレクトリをzipに圧縮します。
S3バケットの用意
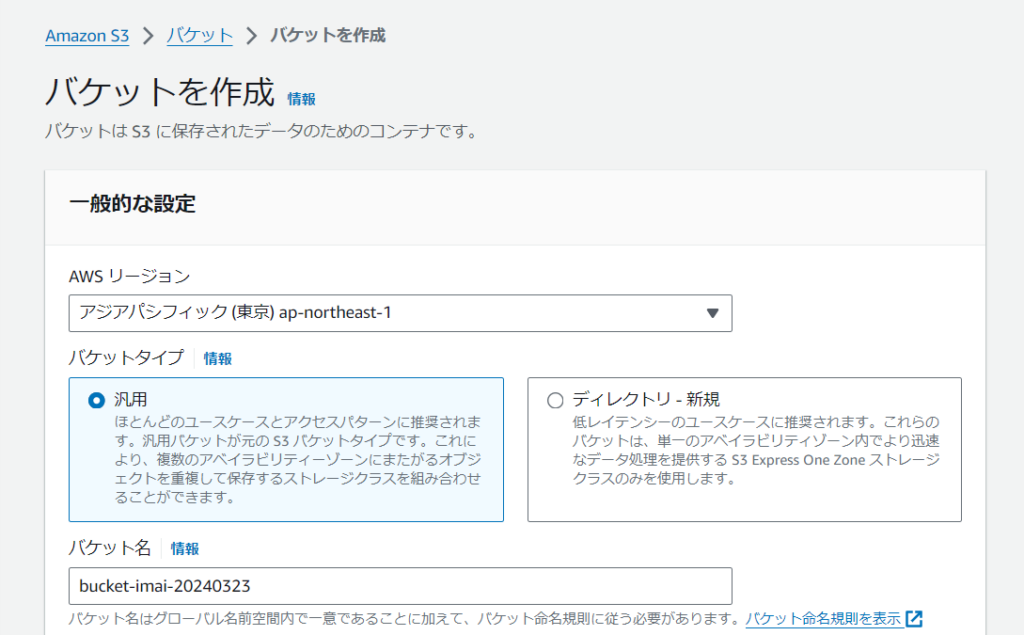
今回はS3トリガーでLambda関数を呼び出すのでS3バケットを用意します。
リージョンを選択して、名前を入力します。
他は特に変更せずに作成します。
レイヤーの作成
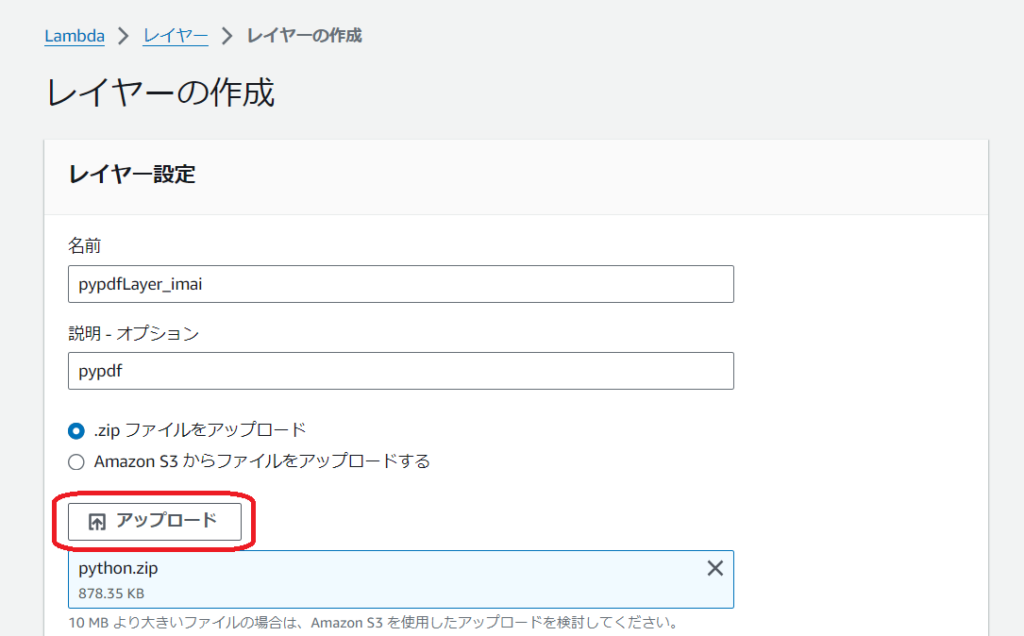
Lambdaの画面からレイヤーを作成します。
名前と説明を入力した後、先ほど圧縮したzipファイルをアップロードします。
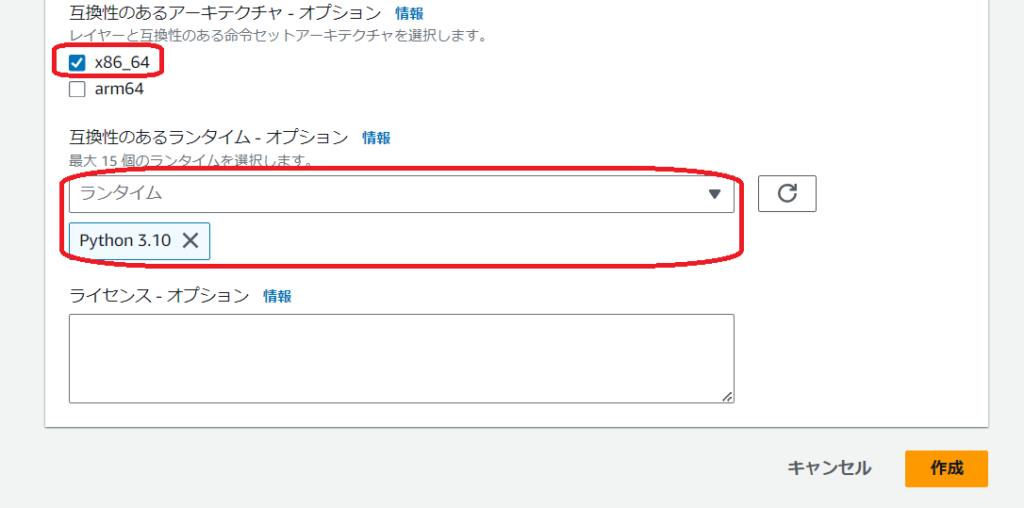
アーキテクチャとランタイムを選択します。
アーキテクチャとランタイムはLambda関数と合わせる必要があります。
今回は設計図を使用してLambda関数を作成するのでx86_64、Python3.10を選択します。
Lambda関数の作成、レイヤーの設定
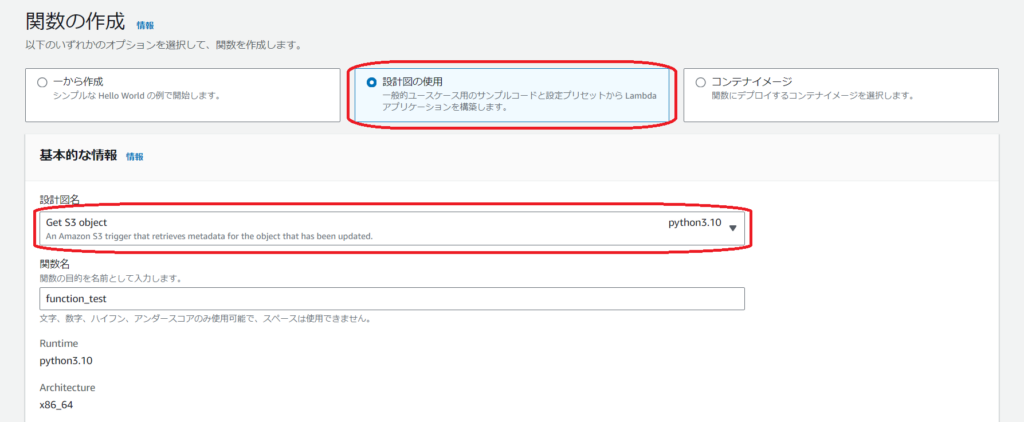
次にLambda関数を作成します。
今回は設計図を使用します。
設計図名はGet S3 objectでランタイムはpython3.10です。
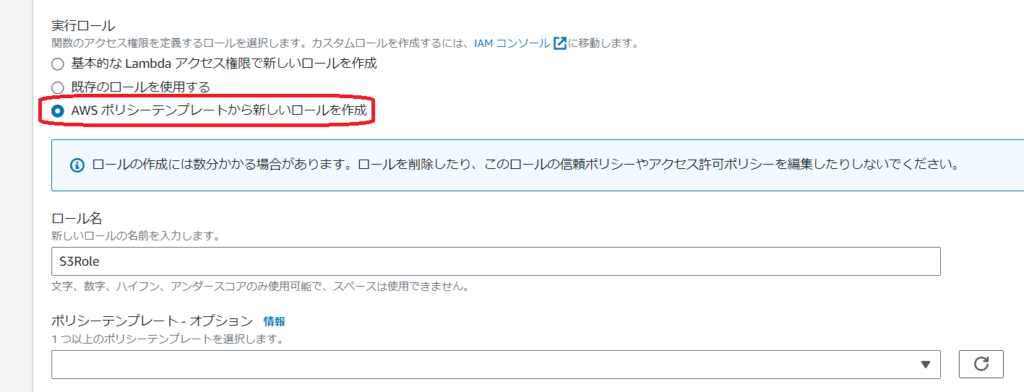
新しくロールを作成して、名前を入力します。
ポリシーは後からアタッチします。
先ほど作成したS3バケットを選択してイベントタイプはAll object create eventsを選択します。
チェックボックスにチェックをつけて作成します。
※同じS3バケットの入力と出力の両方の使用が推奨されないこと、この構成は再帰的な呼び出し、Lambdaの使用量の増加、およびコストの増加を引き起こす可能性があることへの同意を求めています。

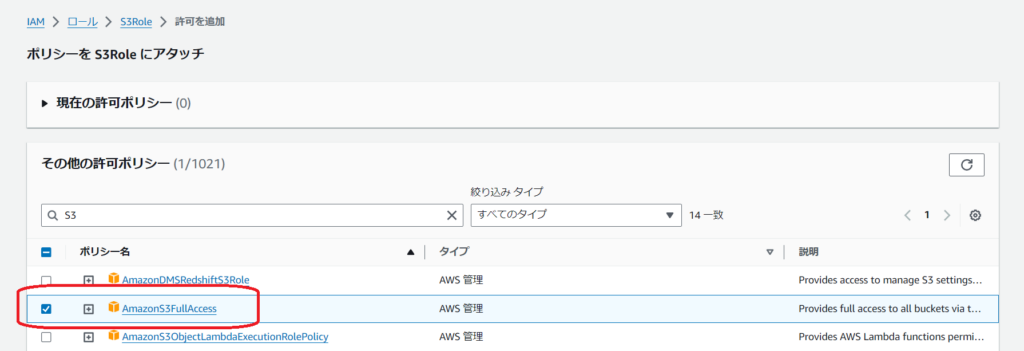
ロールにポリシーをアタッチ
S3を操作するために先ほど作成したロールにポリシーをアタッチします。
IAMの画面からAmzonS3FullAccessを追加します。
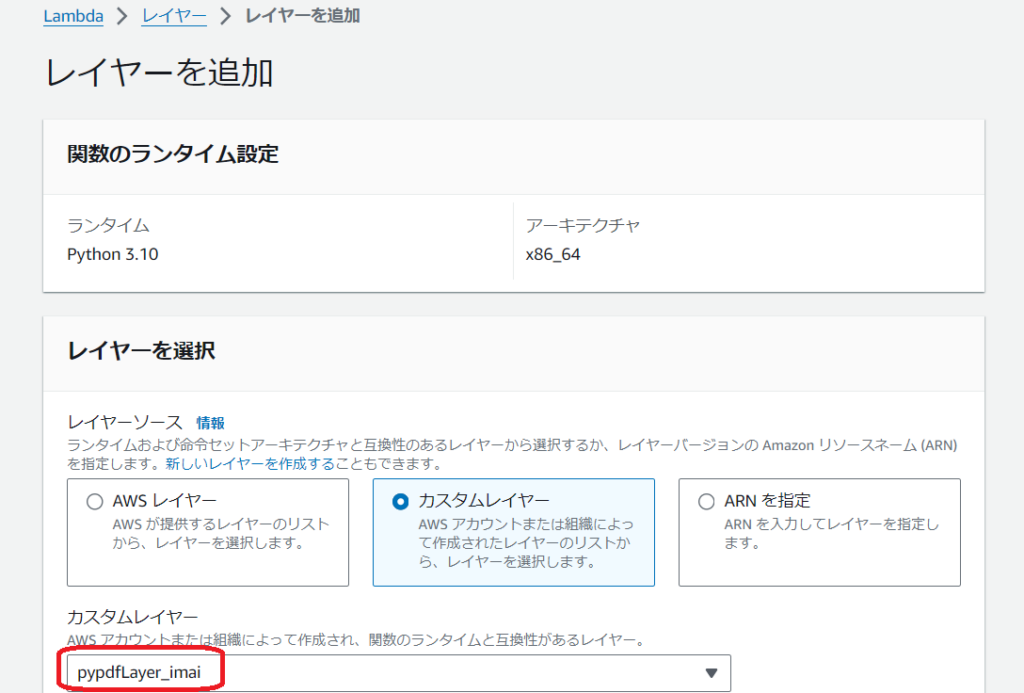
レイヤーの設定
作成したLambda関数にpypdfをアップロードしたレイヤーを追加します。
カスタムレイヤーから作成したレイヤーを選択します。
Pythonを書く
今回はPDFからテキストを取得するので、先ほどレイヤーに追加したpypdfのPdfReaderをインポートします。
import urllib.parse
import boto3
from pypdf import PdfReader
from io import BytesIO
s3_resource = boto3.resource('s3')
def lambda_handler(event, context):
# イベントからオブジェクトを取得
bucket_name = event['Records'][0]['s3']['bucket']['name']
file_name = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
# 元のバケットを取得
source_bucket = s3_resource.Bucket(bucket_name)
# オブジェクトを生成
file_object = source_bucket.Object(file_name)
# bodyを取得
body = file_object.get()['Body'].read()
# バイナリデータを読み込み
file_data = BytesIO(body)
# PDFファイルを読み込み
reader = PdfReader(file_data)
# 1ページ目
page1 = reader.pages[0]
# テキストを抽出して表示
print(page1.extract_text())
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e実行
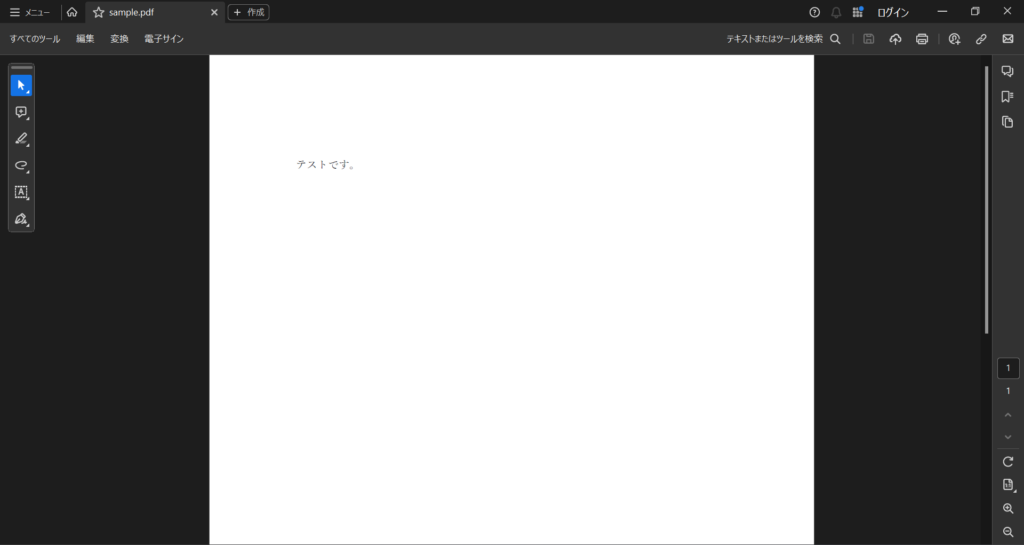
テスト用にPDFを用意します。
実行後、CloudWatchログストリームに「テストです。」と表示されればOKです。
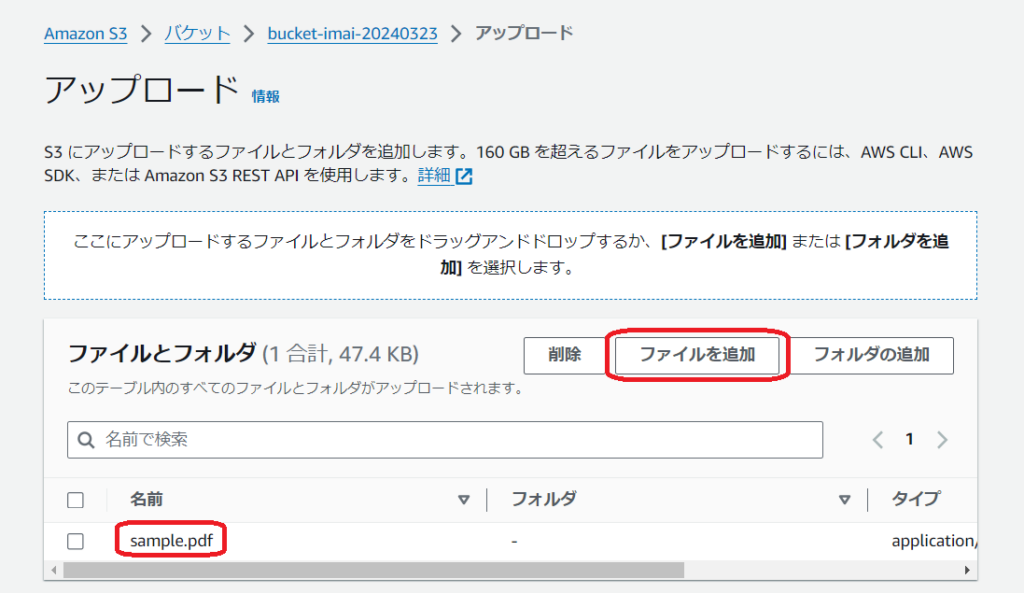
PDFファイルのアップロード
今回は前述した通り、S3トリガーでLambda関数を呼び出すので、先ほど用意したPDFファイルをS3にアップロードします。
実行結果の確認
CloudWatchのログストリームを確認します。
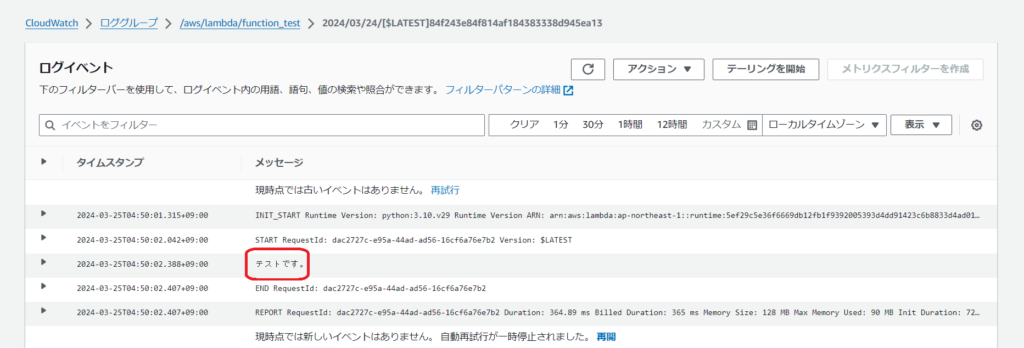
先ほど用意したPDFのテキストが出力されます。
これで、pypdfを使用して、PDFからテキストを取得できたと思います。
おわりに
今回はLambdaのS3トリガーで、pypdfを使用してPDFからテキストを取得しました。
外部ライブラリをレイヤに追加することでLambdaでできることが広がったと思います。
業務でPDFを使う機会が多いので今後はPDFの分割や結合に挑戦していきたいと思います。


コメント